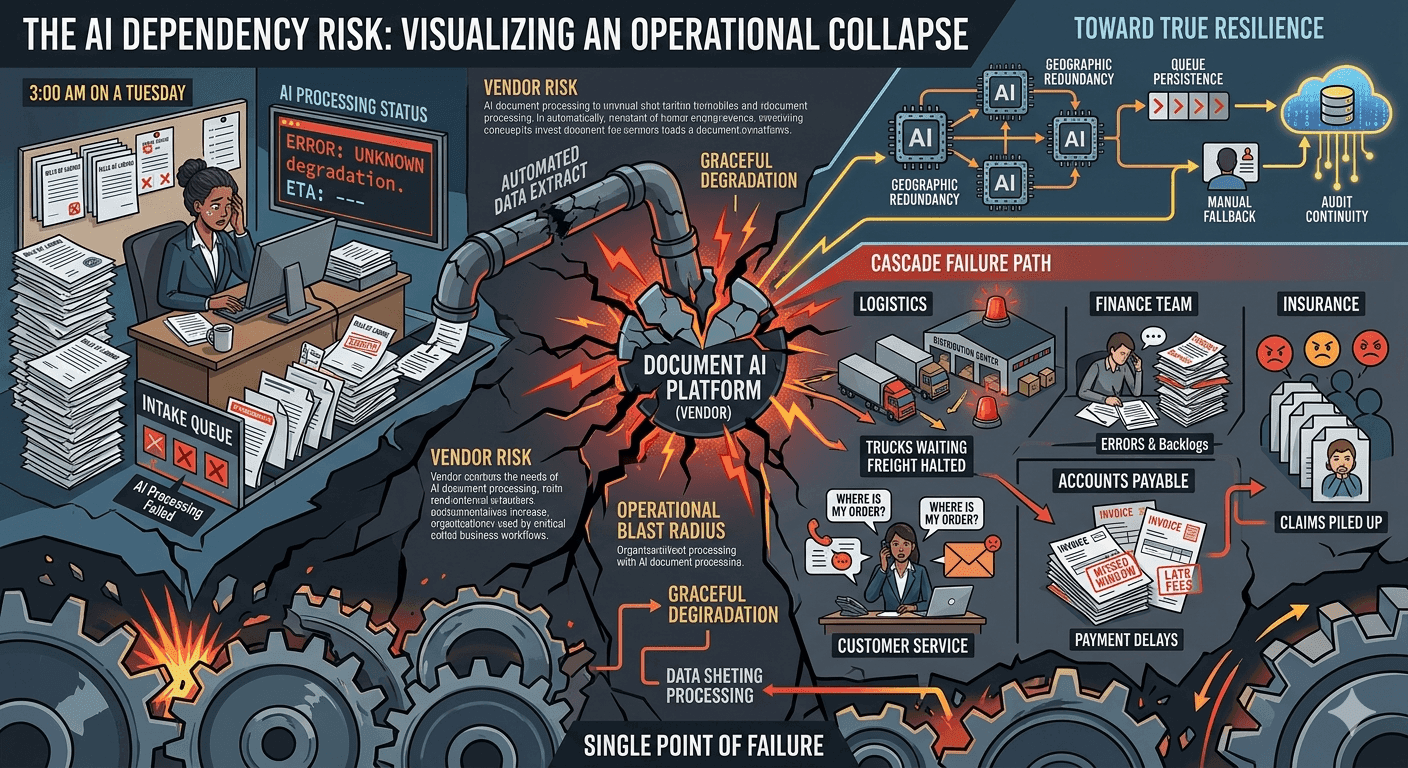
It's 3 a.m. on a Tuesday. A logistics coordinator at a freight company needs to process 40 bills of lading before the morning dispatch window closes. She opens the platform. The document AI is down. The vendor's status page shows a vague "service degradation" message with no ETA. The shipments wait. The drivers wait. The customers, who expect their deliveries that morning, know nothing yet.
This scenario plays out across industries more often than AI vendors like to admit. As organizations shift their document workflows onto AI-powered platforms, they're also quietly building a single point of failure into operations that used to be distributed, manual, and, in their own slow way, resilient. When the AI goes down, it doesn't just slow things down. It stops them entirely.
Business continuity planning has covered network outages, server failures, and natural disasters for decades. It rarely covers the question: what happens to our documents when our AI vendor has an incident?
The Hidden Dependency You Probably Don't Have a Plan For
Most organizations understand vendor risk in the abstract. They negotiate SLAs, check uptime guarantees, and ask about data residency. What they're less likely to examine is the operational blast radius when that vendor goes offline.
AI document processing has become the connective tissue between intake and action in document-heavy industries. Claims don't get paid until documents are classified and extracted. Invoices don't get routed until fields are captured and validated. Shipments don't move until the paperwork clears. Legal teams can't begin review until contracts are sorted and summarized. All of that work now runs through a layer that didn't exist five years ago, and that layer has an uptime number attached to it.
Even vendors with 99.9% uptime guarantees build in roughly 8.7 hours of permissible downtime per year. At 99.5%, that's 43 hours. For document-heavy operations running on tight turnaround windows, a four-hour outage at the wrong time can cascade into a full day of backlog. Multiply that across the teams and systems that depend on clean document outputs, and the business impact far exceeds whatever the vendor's SLA credits reimburse.
The gap isn't just technical. It's conceptual. Organizations tend to think about AI document processing as software, and they think about software outages the way they think about a printer going offline. Annoying, but fixable. The reality is that modern AI document processing sits at the intersection of multiple critical workflows, and its failure propagates in ways that are hard to predict until they happen.
What Actually Breaks: The Cascade Nobody Maps
When AI document processing goes down, the immediate effect is obvious: documents stop getting processed. But the downstream effects build quickly and reach further than most teams realize.
In accounts payable, unprocessed invoices mean payment runs get delayed. Vendors miss payment windows. Early payment discounts disappear. Reconciliation timelines slip. Finance teams that relied on automated data capture switch to manual entry, which introduces errors and takes three times as long. Month-end close gets complicated.
In logistics, unprocessed shipping documents mean goods sit in limbo. Customs clearance that depends on validated documentation stalls. Carriers miss handoff windows. Customer SLAs get breached. The operations team starts making phone calls instead of processing documents, which absorbs capacity that should be going to exception handling.
In insurance, claims that can't be ingested and triaged pile up. Adjusters don't get their work queues populated. Response time metrics slip. Policyholders who filed claims in good faith wait longer than they should, sometimes in genuinely difficult circumstances.
In healthcare, referrals and prior authorizations that depend on document extraction sit unactioned. Clinical workflows get disrupted. Administrative staff pivot to workarounds that are inconsistent across individuals.
The point isn't that these failures are catastrophic in isolation. It's that they compound. Each delayed step pushes the next one further back. And because modern document workflows are deeply integrated with ERP systems, CRMs, and case management platforms, the failure doesn't stay in the document layer. It propagates upstream into every system that was waiting for clean data.
How Most Vendors Handle Downtime (and Why It's Not Enough)
The standard vendor approach to downtime is reactive. Something breaks, the engineering team responds, a status page gets updated, and affected customers receive a post-incident report explaining what happened. This approach works reasonably well for software tools that sit at the periphery of business operations. It works much less well when the software sits at the center of critical document workflows.
The most common vendor response to a customer asking "what's our fallback?" is something like "we have redundant infrastructure" or "our SLA covers X% uptime." These answers address infrastructure reliability. They don't address operational continuity. Redundant infrastructure means the vendor has designed their own systems to recover quickly. It says nothing about what you, the customer, can do while they recover.
True business continuity in AI document processing requires thinking about three distinct layers. The first is vendor resilience, meaning the vendor's own ability to avoid and recover from incidents. The second is platform design, meaning whether the platform you're using is built to degrade gracefully rather than fail completely. The third is your own operational preparedness, meaning whether your team has runbooks, manual fallback procedures, and queue management strategies for a processing outage.
Most organizations have thought carefully about the first layer and almost not at all about the second and third.
What Good Resilience Actually Looks Like
The characteristics that make AI document processing genuinely resilient aren't the ones that appear most prominently in vendor marketing materials. They're architectural and operational.
Geographic redundancy means your document processing doesn't live in a single region. If one data center has an incident, processing fails over to another. This is foundational infrastructure, but it's worth asking your vendor specifically whether their AI processing layer (not just their storage layer) is geographically distributed.
Processing isolation means that when one component of the system has a problem, it doesn't bring everything else down with it. Well-designed platforms separate the AI processing pipeline from the workflow orchestration layer, the integration layer, and the user interface. An extraction model that degrades shouldn't mean the entire platform goes dark.
Queue persistence means that documents submitted during a degraded period don't disappear. They wait. When processing capacity comes back online, the queue drains in order. Organizations should ask vendors specifically: if I submit documents during a degraded period, what happens to them? Are they held? Are they dropped? Are they returned with an error?
Graceful degradation is the ability for a platform to continue functioning at reduced capacity during a partial outage. A well-designed system might route documents to a secondary extraction method, flag them for human review, or hold them in a confirmed queue, rather than returning a failure response that leaves the operator with no idea what to do next.
Audit continuity matters for regulated industries. During an outage, organizations need to know which documents were processed successfully, which are queued, and which failed. Without that visibility, teams can't prioritize their manual recovery work, and compliance teams can't demonstrate control during incident reviews.
Data portability is a resilience question that most buyers only think about at contract renewal time, but it's actually a business continuity concern. If your vendor has an extended outage, can you export your document models, your extraction configurations, and your workflow templates to another platform? Or are you stuck waiting?
Asking the Right Questions Before You're in a Crisis
The time to understand your vendor's resilience posture is not at 3 a.m. when processing has been down for two hours and your escalation path hits a generic support queue. It's during procurement, renewal, and your next quarterly business review.
The questions worth asking go beyond uptime percentages. Ask what the vendor's recovery time objective is for critical processing functions. Ask whether they differentiate between their platform being unavailable versus their AI models being degraded. These are different failure modes with different operational impacts.
Ask what happens to documents submitted during an incident. Ask whether you can configure fallback behavior at the workflow level: for example, automatically flagging documents for manual review when AI confidence scores fall below a threshold, rather than failing silently.
Ask about their incident communication process. Is their status page manually updated or automatic? How quickly do they notify customers when an incident is declared? Do enterprise customers get direct communication from a named contact, or does communication happen through a generic status page?
Ask about planned maintenance windows and whether they can be scheduled around your peak processing periods. A vendor that does maintenance on Tuesday nights at 2 a.m. UTC without considering where their customers are operating is a vendor that hasn't thought seriously about your operational context.
Building Your Own Operational Resilience
Even with a well-designed vendor platform, your organization needs its own continuity layer. This isn't a criticism of AI document processing. It's the same discipline that good IT teams apply to every critical system.
Start with a document workflow inventory. Map which document types flow through AI processing, which downstream systems depend on them, and what the operational impact is if processing is delayed by one hour, four hours, or 24 hours. This inventory tells you which workflows are genuinely time-critical and which can tolerate a backlog window.
For time-critical workflows, document a manual fallback procedure. This doesn't mean printing everything out. It means knowing which team members can perform expedited manual review, which templates or reference documents they need, and how the queue gets managed and prioritized during the recovery period. A runbook doesn't need to be elaborate. It needs to exist and to be practiced at least once before the actual outage.
For workflows that feed downstream systems, understand the buffer tolerance. Most ERP and case management systems can absorb a processing delay up to a point before it starts affecting external commitments. Knowing that threshold helps your team make better prioritization decisions during an incident.
Consider negotiating contractual provisions around incident response time, direct escalation contacts for production outages, and credit structures that reflect actual operational impact rather than just raw uptime percentages. Vendors who've thought seriously about enterprise resilience expect these conversations. Vendors who haven't are telling you something important about their priorities.
The Bigger Picture: AI Dependency as Operational Risk
The business case for AI document processing is strong. The time savings are real. The accuracy improvements are real. The capacity gains are real. None of that changes the fact that when you automate a critical workflow, you take on a dependency, and that dependency needs to be managed like any other operational risk.
The organizations that handle AI vendor incidents best aren't the ones who assumed the vendor would never go down. They're the ones who planned for it, built fallback capacity, asked hard questions about platform design, and treated document processing resilience as a discipline rather than an afterthought.
AI is moving fast in the document processing space. The platforms are getting better every quarter. But the fundamentals of operational resilience don't change because the technology is newer. You still need redundancy. You still need fallback procedures. You still need clear escalation paths and practiced recovery workflows.
Your documents are only as resilient as the infrastructure they move through. And that infrastructure deserves the same scrutiny you'd give any other critical operational system.