
Introduction
The digital transformation of modern enterprises has brought to light a significant challenge that organizations face: the vast amount of valuable information trapped within unstructured documents. These documents, ranging from handwritten notes and legacy papers to complex multi-format files, represent a treasure trove of potential insights that remain largely inaccessible through conventional data processing methods. The emergence of advanced Optical Character Recognition (OCR) technology, particularly when enhanced with artificial intelligence and machine learning capabilities, presents a powerful solution to this long-standing challenge.
The magnitude of this challenge becomes apparent when considering that unstructured data constitutes approximately 80-90% of all enterprise data, with the volume growing at a rate of 55-65% annually. This exponential growth, coupled with the increasing need for rapid data access and analysis, has created a pressing demand for sophisticated solutions capable of efficiently processing and extracting valuable information from these documents. Traditional manual processing methods have proven inadequate in handling this volume, often resulting in significant backlogs, high error rates, and missed opportunities for insight extraction.
The complexity of unstructured document analysis extends beyond simple character recognition to encompass understanding document context, identifying relationships between different elements, and extracting meaningful insights from varied formats and layouts. The integration of sophisticated OCR technology with advanced analytics capabilities has opened new possibilities for unlocking this hidden data, enabling organizations to transform unstructured documents into valuable, actionable information. This technological advancement represents a fundamental shift in how organizations approach document processing and knowledge management.
The Challenge of Unstructured Documents
The nature of unstructured documents presents a multifaceted challenge that encompasses various technical, operational, and analytical complexities. At its core, the primary challenge lies in the inherent variability of unstructured documents, which lack predetermined formatting or organization. This variability manifests in multiple dimensions, including layout variations, content organization, and data presentation formats. Documents may combine different elements such as text blocks, tables, images, and annotations in unpredictable ways, creating complexity in automated processing attempts.
Document quality variations represent another significant challenge in processing unstructured documents. Historical documents may suffer from degradation, including fading, staining, or physical damage. Modern documents might present issues related to scanning quality, resolution variations, or digital artifacts. These quality issues can significantly impact the accuracy of character recognition and data extraction processes. Furthermore, the presence of handwritten annotations, stamps, or other manual modifications adds additional layers of complexity to the processing requirements.
The semantic complexity of unstructured documents poses particular challenges for automated processing systems. Documents often contain context-dependent information where the meaning of text elements depends on their relationship to other document components. Technical documents may employ domain-specific terminology that requires specialized understanding for accurate interpretation. The presence of implied relationships between different document sections further complicates the extraction of meaningful information.
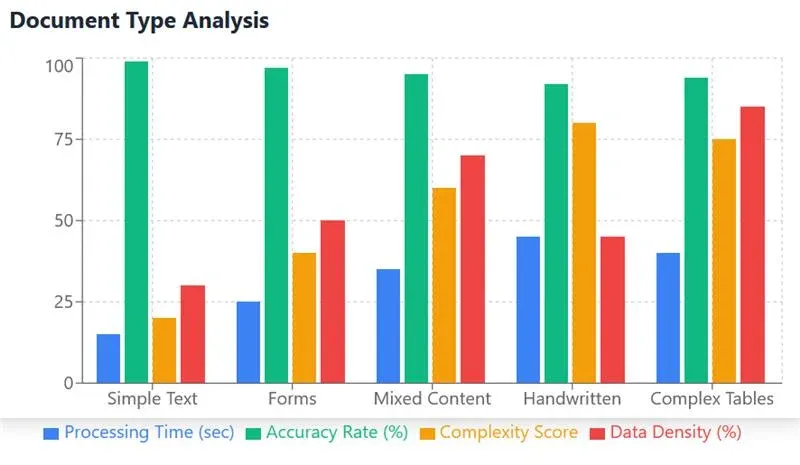
Language and formatting variations add another dimension of complexity to unstructured document processing. Documents may contain multiple languages, varying font styles, or non-standard character sets. The use of specialized notation, symbols, or industry-specific formats requires sophisticated recognition capabilities. Additionally, the presence of tables, charts, or other structured elements within otherwise unstructured documents necessitates adaptive processing approaches capable of handling these varied content types.
Technological Framework for Unstructured Document Analysis
The processing of unstructured documents through OCR technology relies on a sophisticated technological framework that combines multiple processing layers and analytical capabilities. At the foundation of this framework lies the document preprocessing layer, which employs advanced image processing algorithms to optimize document quality for subsequent analysis. This preprocessing stage includes multiple specialized components designed to address various document quality issues and prepare content for optimal recognition.
Image enhancement algorithms play a crucial role in the preprocessing stage, implementing various techniques to improve document quality. These algorithms address issues such as noise reduction, contrast optimization, and geometric correction. Advanced techniques including adaptive thresholding, morphological operations, and perspective correction ensure consistent processing results across different document conditions. The preprocessing stage 
also implements specialized handling for different document types, adjusting processing parameters based on document characteristics and quality metrics.
The core recognition engine represents the heart of the processing framework, implementing multiple specialized neural networks optimized for different aspects of document processing. These networks employ various architectural approaches, including convolutional neural networks (CNNs) for image analysis, recurrent neural networks (RNNs) for sequence processing, and transformer models for contextual understanding. The combination of these different neural network architectures enables the system to handle complex document structures while maintaining high accuracy levels.
Layout analysis capabilities form a crucial component of the processing framework, enabling understanding of document structure and organization. These capabilities employ sophisticated algorithms for segment detection, content classification, and relationship analysis. Advanced techniques including hierarchical layout analysis and geometric relationship modeling enable accurate interpretation of complex document structures. The layout analysis component also implements specialized handling for different document elements, including tables, forms, and mixed-content sections.
Advanced Analytics and Content Understanding
The extraction of meaningful information from unstructured documents requires sophisticated analytics capabilities that extend beyond basic character recognition. These analytics capabilities implement various techniques for content understanding, relationship identification, and insight extraction. Natural language processing (NLP) plays a crucial role in this analysis, enabling understanding of document context and meaning.
Semantic analysis capabilities enable the system to understand the meaning and context of extracted text. These capabilities employ various NLP techniques, including named entity recognition, relationship extraction, and sentiment analysis. Advanced language models enable understanding of domain-specific terminology and context-dependent meanings. The integration of knowledge graphs and ontologies enables identification of relationships between different content elements.
Machine learning algorithms enable continuous improvement of processing capabilities through learning from experience. These algorithms analyze processing patterns, identify common error types, and adapt recognition parameters to improve accuracy. Advanced techniques including transfer learning and few-shot learning enable rapid adaptation to new document types with minimal additional training data. The system's ability to learn from processing patterns ensures continuous improvement in recognition accuracy and content understanding.
Implementation Methodology and Best Practices
The successful implementation of OCR for unstructured document analysis requires a structured approach that addresses both technical and operational considerations. The implementation methodology must consider various factors including document characteristics, processing requirements, and integration needs. Organizations must develop comprehensive implementation strategies that ensure optimal system performance while maintaining user adoption and operational efficiency.
The implementation process typically begins with detailed analysis of document types and processing requirements. This analysis includes assessment of document volumes, format variations, and quality characteristics. Organizations must establish clear protocols for document handling, including guidelines for document preparation and quality standards. The implementation strategy must also address integration requirements, ensuring seamless connection with existing systems while maintaining data consistency and accessibility.
Change management represents a crucial aspect of successful implementation. Organizations must develop comprehensive training programs that address the needs of different user groups. These programs should include hands-on training sessions, detailed documentation, and ongoing support mechanisms. The change management strategy must address cultural and organizational factors that might impact adoption, including resistance to automation and concerns about job displacement.
Impact Analysis and Performance Metrics
The implementation of OCR technology for unstructured document analysis demonstrates significant impact across various operational dimensions. Organizations report substantial improvements in processing efficiency, accuracy, and data accessibility. These improvements translate into tangible benefits including cost reduction, improved decision-making capabilities, and enhanced operational efficiency.
Performance metrics indicate significant improvements in document processing capabilities, with organizations achieving accuracy rates exceeding 95% for complex unstructured documents. Processing time reductions of 60-80% compared to manual methods demonstrate the efficiency gains possible through automated processing. The ability to process large document volumes while maintaining consistent accuracy levels enables organizations to handle increasing document requirements without proportional resource increases.
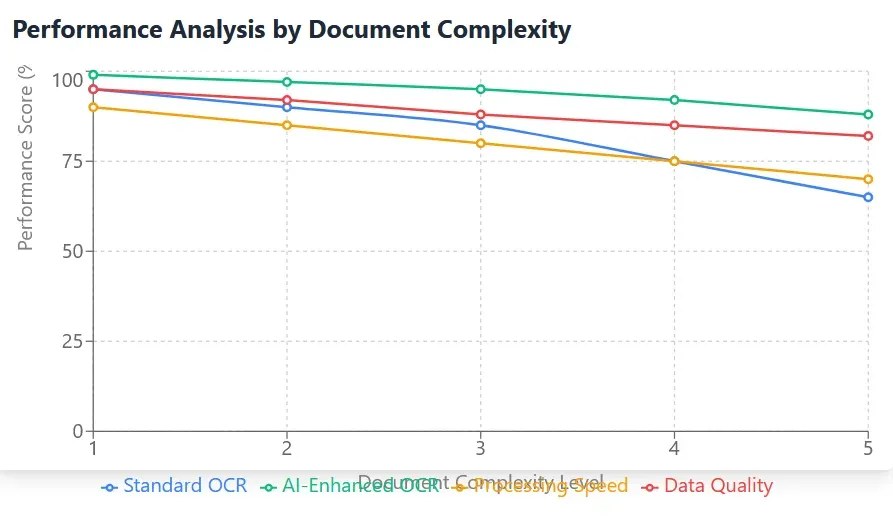
Cost analysis demonstrates compelling return on investment for OCR implementation in unstructured document processing. Organizations report significant reductions in processing costs, typically achieving 40-60% cost savings compared to manual processing methods. These cost reductions result from various factors including reduced labor requirements, improved processing efficiency, and decreased error correction needs. The ability to handle increased document volumes without proportional cost increases provides valuable scalability advantages.
Future Trends and Technical Evolution
The evolution of OCR technology continues to advance, driven by developments in artificial intelligence and machine learning. Emerging trends indicate increasing sophistication in content understanding capabilities, improved handling of complex document types, and enhanced integration with other technologies. These developments suggest continued improvement in the ability to process and analyze unstructured documents effectively.
Advanced neural network architectures represent a particularly promising area for future development. These architectures implement sophisticated attention mechanisms and improved learning capabilities, enabling better handling of complex document structures and relationships. The integration of quantum computing capabilities may enable new approaches to pattern recognition and feature extraction, potentially revolutionizing processing capabilities for complex documents.
Conclusion
The role of OCR technology in unlocking hidden data from unstructured documents represents a significant advancement in organizational data processing capabilities. The technology's ability to effectively process diverse document types while maintaining high accuracy levels enables organizations to access previously inaccessible information, improving decision-making capabilities and operational efficiency. The continuous evolution of OCR technology, particularly in areas of artificial intelligence and machine learning, suggests further improvements in processing capabilities and accuracy levels.
The successful implementation of OCR for unstructured document analysis requires careful consideration of both technical and operational factors. Organizations must approach implementation as a strategic initiative that requires comprehensive planning and execution. The demonstrated benefits in terms of processing efficiency, accuracy, and data accessibility make OCR technology an essential tool for organizations seeking to leverage their unstructured document resources effectively.