
Introduction
The digital transformation of business processes has reached a critical inflection point, with Optical Character Recognition (OCR) technology emerging as a transformative force in the realm of data entry and document processing. This technological revolution represents far more than a mere automation tool, it constitutes a fundamental reimagining of how organizations handle information processing and management. As enterprises grapple with exponentially increasing volumes of data and documents, the integration of OCR technology has become not just advantageous but imperative for maintaining competitive advantage in an increasingly digital marketplace. This comprehensive analysis explores the transformative impact of OCR technology on modern business operations, examining its technological foundations, implementation strategies, and the profound implications for organizational efficiency and competitive positioning.
The Evolution of Data Entry: From Manual to Intelligent Processing
The trajectory of data entry processes in enterprise environments represents a remarkable evolution spanning multiple technological epochs, each marked by significant advancements in processing capabilities and operational efficiency. This evolutionary journey, from rudimentary manual processes to sophisticated AI-powered systems, reflects broader technological transformations in the business landscape while highlighting the increasing importance of efficient data processing in modern enterprises.
The initial phase of data entry, characterized by purely manual processes, relied entirely on human operators transcribing information from physical documents into digital systems. This era, while fundamental in establishing basic digitization practices, was marked by significant limitations in processing speed, accuracy, and scalability. Organizations faced substantial challenges in managing large document volumes, maintaining consistent quality standards, and addressing the inherent inefficiencies of manual processing. The human-centric nature of these operations introduced various challenges, including fatigue-induced errors, inconsistent processing speeds, and substantial training requirements for maintaining operational standards.
The emergence of early automated systems in the 1990s marked the beginning of a transformative period in data entry operations. These initial systems, though limited in capability, introduced basic character recognition functionalities that could process standardized documents with moderate accuracy. However, these early solutions struggled with variations in document format, quality, and content structure, often requiring significant human intervention for error correction and validation. The limitations of these systems became particularly apparent when dealing with complex documents, multiple languages, or poor-quality inputs, highlighting the need for more sophisticated processing capabilities.
The integration of advanced pattern recognition algorithms and machine learning capabilities in the early 2000s represented a significant leap forward in automated data entry capabilities. These systems introduced more sophisticated character recognition algorithms capable of handling various font styles, document formats, and quality levels. The implementation of neural networks and pattern recognition algorithms enabled these systems to achieve higher accuracy rates while reducing the need for human intervention. This period also saw the introduction of context-aware processing capabilities, enabling systems to understand and interpret information based on document context and content relationships.
The current era of intelligent data entry systems, powered by sophisticated artificial intelligence and machine learning algorithms, represents the culmination of this evolutionary journey. Modern OCR systems employ advanced neural networks capable of learning from experience, adapting to new document types, and continuously improving their processing accuracy. These systems integrate multiple AI technologies, including computer vision, natural language processing, and deep learning, to create comprehensive document understanding capabilities. The ability to handle unstructured data, recognize complex patterns, and make context-aware decisions has transformed OCR from a simple character recognition tool into an intelligent document processing platform.
This technological evolution has fundamentally altered how organizations approach data entry operations. The shift from reactive, labor-intensive processes to proactive, intelligent systems has enabled organizations to achieve unprecedented levels of efficiency and accuracy. Modern OCR systems can process diverse document types while maintaining high accuracy levels, automatically adapt to new formats and patterns, and integrate seamlessly with existing business systems. This transformation has not only improved operational efficiency but has also enabled organizations to redirect human resources from routine data entry tasks to higher-value activities requiring cognitive skills and decision-making capabilities.
Economic Implications and ROI Analysis
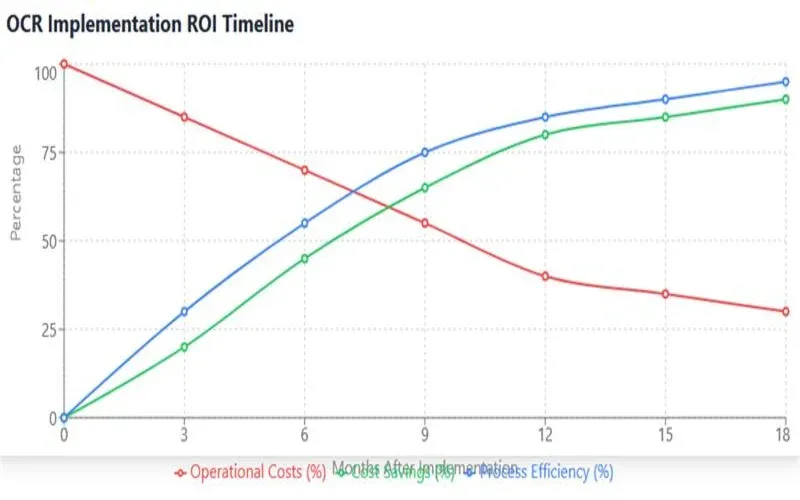
The implementation of OCR technology in enterprise environments presents compelling economic advantages that extend far beyond immediate cost reduction. A comprehensive analysis of return on investment reveals multifaceted benefits that impact various aspects of organizational operations. The direct cost savings from reduced manual data entry requirements represent only the initial layer of economic benefit. Organizations implementing OCR systems typically observe a 60-80% reduction in data entry costs within the first year of deployment, with these savings increasing as the system learns and improves over time.
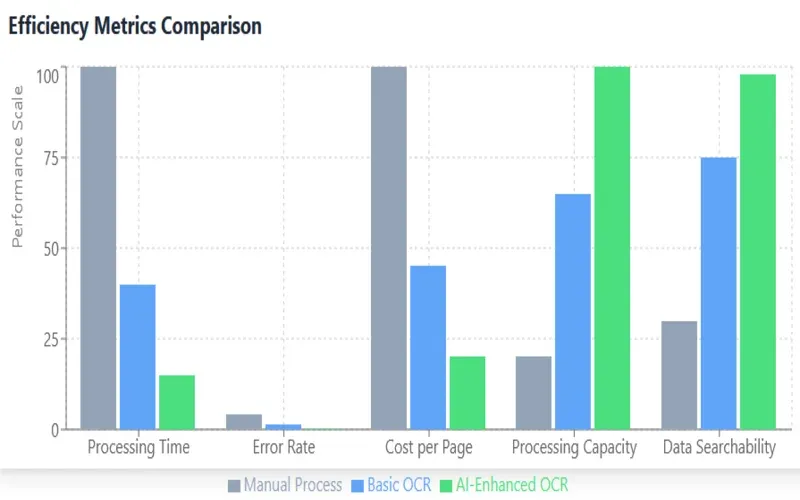
The economic impact extends to improved data accuracy and reduced error correction costs. Traditional manual data entry typically results in error rates between 1% and 4%, while modern OCR systems achieve accuracy rates exceeding 99% for standardized documents. This improvement in accuracy translates to substantial cost savings in error correction, validation, and downstream process optimization. Furthermore, the reduction in processing time from hours to minutes for standard documents enables organizations to reallocate human resources to higher-value activities, creating additional economic benefits through improved workforce utilization.
Technological Architecture and Implementation Framework
The successful deployment of OCR as a transformative data entry solution necessitates a sophisticated technological architecture that seamlessly integrates multiple specialized components into a cohesive, scalable system. This architectural framework must address not only immediate processing requirements but also accommodate future scalability needs while maintaining system reliability and performance. The complexity of modern OCR systems requires careful consideration of various architectural elements, from fundamental preprocessing capabilities to advanced AI integration and data validation mechanisms.
At the foundation of the architecture lies a robust document intake and preprocessing layer that serves as the system's first line of defense against quality variations and format inconsistencies. This layer incorporates sophisticated image enhancement algorithms that address common document quality issues, including noise reduction, contrast optimization, and geometric correction. Advanced preprocessing capabilities employ adaptive algorithms that automatically adjust processing parameters based on document characteristics, ensuring optimal preparation for subsequent recognition stages. The preprocessing layer also includes specialized modules for handling various document formats, from simple text documents to complex multi-column layouts and tables.
The core recognition engine represents the system's technological centerpiece, incorporating multiple specialized neural network architectures optimized for different aspects of document processing. This engine employs a sophisticated ensemble of convolutional neural networks (CNNs) for feature extraction, recurrent neural networks (RNNs) for sequence processing, and transformer models for contextual understanding. The integration of these various neural network architectures enables the system to handle complex document structures while maintaining high accuracy levels across different document types and formats.
The system's architecture includes a dedicated layout analysis component that employs advanced computer vision algorithms to understand document structure and organization. This component utilizes sophisticated segmentation algorithms that can identify and separate different document elements, including text blocks, tables, images, and form fields. The layout analysis engine employs hierarchical processing approaches that consider both local and global document characteristics, enabling accurate interpretation of complex document structures and relationships between different elements.
Data validation and quality assurance mechanisms form an integral part of the system architecture, incorporating multiple validation layers that ensure accuracy and reliability of extracted information. These mechanisms employ rule-based validation engines that verify extracted data against predefined patterns and business rules, while also utilizing machine learning models for context-aware validation. The architecture includes specialized modules for handling industry-specific validation requirements, enabling customization of validation rules based on specific business needs and compliance requirements.
The system's persistent storage and retrieval architecture employs sophisticated database designs that optimize data organization and access patterns. This includes implementation of specialized indexing strategies that enable rapid data retrieval and searching capabilities, while also maintaining data relationships and document context. The storage architecture incorporates advanced compression algorithms that optimize storage utilization while maintaining rapid access capabilities, enabling efficient handling of large document volumes while minimizing storage costs.
Integration capabilities represent a crucial architectural consideration, with the system incorporating multiple standardized interfaces that enable seamless connection with existing enterprise systems. The architecture implements various integration patterns, including REST APIs, message queues, and event-driven architectures, providing flexibility in system integration approaches. These integration capabilities enable real-time data exchange with other enterprise systems while maintaining data consistency and processing efficiency.
Security considerations permeate every aspect of the system architecture, with multiple security layers ensuring data protection throughout the processing pipeline. The architecture implements sophisticated encryption mechanisms for data in transit and at rest, while also incorporating advanced access control mechanisms that enable granular control over system functionality and data access. The security architecture includes comprehensive audit logging capabilities that maintain detailed records of all system activities, enabling compliance with various regulatory requirements while providing visibility into system operations.
Process Transformation and Organizational Impact
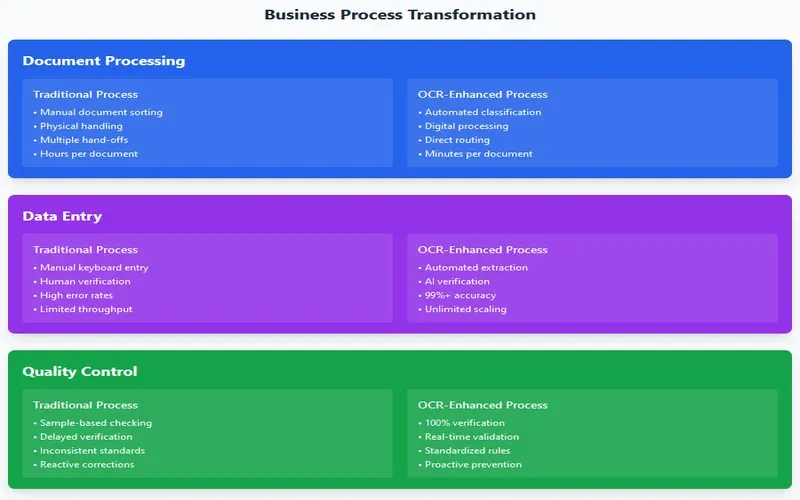
The implementation of OCR technology catalyzes a fundamental transformation in organizational processes that extends beyond mere automation. This transformation necessitates a comprehensive reassessment of existing workflows, document management systems, and business processes. Organizations must develop sophisticated integration strategies that align OCR capabilities with existing systems while ensuring seamless data flow between different components of the enterprise architecture. The process transformation extends to the development of new workflows that capitalize on the enhanced processing capabilities while maintaining necessary controls and validation mechanisms.
The organizational impact of OCR implementation manifests in various dimensions, including changes in job roles, skill requirements, and operational procedures. The transition from manual to automated data entry necessitates the development of new competencies among staff members, focusing on system oversight, exception handling, and quality control rather than routine data entry tasks. This shift requires comprehensive change management strategies that address both technical and human aspects of the transformation, ensuring successful adoption and utilization of the new technology.
Security Considerations and Compliance Requirements
The implementation of OCR technology in enterprise environments necessitates careful consideration of security implications and compliance requirements. Organizations must develop robust security frameworks that protect sensitive information throughout the document processing lifecycle, from initial capture to final storage. This includes implementing encryption mechanisms for data in transit and at rest, establishing access control protocols, and maintaining comprehensive audit trails of all document processing activities.
Compliance considerations vary across industries and jurisdictions, requiring careful attention to regulatory requirements in system configuration and operation. Organizations must ensure that OCR implementations adhere to relevant data protection regulations, industry standards, and internal governance requirements. This includes implementing appropriate data retention policies, establishing security controls, and maintaining documentation of compliance measures.
Future Trends and Technological Evolution
The future trajectory of OCR technology in enterprise data entry environments presents a fascinating convergence of multiple technological innovations that promise to revolutionize document processing capabilities. This evolution encompasses various technological frontiers, from quantum computing applications to advanced AI implementations, each offering unique possibilities for enhancing system capabilities and processing efficiency. Understanding these emerging trends and their potential impact is crucial for organizations planning their future technology strategies and investments in document processing capabilities.
The integration of quantum computing technologies represents perhaps the most transformative potential advancement in OCR processing capabilities. Quantum algorithms, particularly in pattern recognition and feature extraction, could revolutionize how systems process and analyze document content. The ability to simultaneously evaluate multiple possible interpretations of characters and document structures could dramatically improve recognition accuracy while reducing processing time. Quantum-enhanced machine learning algorithms could enable more sophisticated training approaches, potentially allowing systems to learn from smaller datasets while achieving higher accuracy levels. The implementation of quantum-resistant cryptography will become increasingly important as these capabilities evolve, ensuring continued data security in a post-quantum computing environment.
Advanced artificial intelligence implementations, particularly in the realm of natural language processing and understanding, promise to significantly enhance OCR capabilities. The development of transformer-based language models with increasingly sophisticated understanding of context and semantic relationships will enable more accurate interpretation of document content. These advancements will facilitate better handling of ambiguous content, improved error correction capabilities, and more sophisticated document understanding capabilities. The integration of multi-modal AI models that can simultaneously process text, images, and document structure will enable more comprehensive document understanding capabilities.
Edge computing architectures represent another significant trend in OCR technology evolution, offering possibilities for distributed processing that optimizes performance while maintaining data security. The implementation of edge processing capabilities enables real-time document processing at the point of capture, reducing latency and bandwidth requirements while improving system responsiveness. Edge-based preprocessing and initial recognition capabilities can significantly reduce the load on central processing systems while enabling faster response times for users. The development of specialized edge processing hardware optimized for OCR workloads could further enhance these capabilities.
The evolution of neural network architectures specifically optimized for document processing represents another crucial development area. These specialized architectures will likely incorporate attention mechanisms that better handle document structure and relationships, enabling more accurate interpretation of complex documents. The development of more efficient neural network architectures could reduce computational requirements while maintaining or improving accuracy levels. Advanced training methodologies, including few-shot and zero-shot learning capabilities, could enable systems to more rapidly adapt to new document types with minimal additional training data.
Augmented reality and mixed reality technologies present interesting possibilities for enhancing OCR capabilities, particularly in real-time document processing scenarios. The integration of OCR capabilities with AR systems could enable immediate document processing and information overlay capabilities, providing users with real-time access to processed information. These technologies could particularly benefit mobile document processing scenarios, enabling more efficient field-based document processing and validation capabilities.
The integration of blockchain technologies with OCR systems presents opportunities for enhanced document verification and authenticity tracking capabilities. Blockchain-based document verification systems could provide immutable records of document processing and modifications, enabling better tracking of document history and changes. Smart contracts could automate various aspects of document processing workflows, ensuring consistent application of processing rules and requirements.
Privacy-preserving computation techniques, including homomorphic encryption and secure multi-party computation, will likely play an increasingly important role in OCR system evolution. These technologies enable document processing while maintaining data privacy, particularly important in regulated industries and sensitive applications. The development of privacy-preserving OCR capabilities could enable new applications in highly regulated industries while ensuring compliance with evolving privacy regulations.
Conclusion
The transformation of data entry through OCR technology represents a fundamental paradigm shift in how organizations approach information processing and management in the digital age. This transformation extends far beyond simple automation of manual tasks, encompassing a comprehensive reimagining of document processing workflows and organizational capabilities. The integration of sophisticated AI technologies, advanced neural networks, and intelligent processing capabilities has elevated OCR from a basic automation tool to a strategic asset that enables organizations to achieve unprecedented levels of efficiency and accuracy in their document processing operations.
The economic implications of this transformation are profound, with organizations achieving significant cost reductions while simultaneously improving processing accuracy and speed. The ability to process large volumes of documents with minimal human intervention, while maintaining high accuracy levels, has enabled organizations to redirect human resources to higher-value activities that require cognitive skills and decision-making capabilities. This reallocation of resources represents not just an operational efficiency gain but a strategic advantage in an increasingly competitive business environment.
The technological evolution of OCR systems, particularly in the realm of artificial intelligence and machine learning, suggests continued enhancement of capabilities that will further transform document processing operations. The potential integration of quantum computing, edge processing capabilities, and advanced neural network architectures promises to push the boundaries of what is possible in automated document processing. These advancements will likely enable new applications and use cases that are currently impractical or impossible with existing technologies.
The success of OCR implementation in enterprise environments depends heavily on careful consideration of architectural requirements, security implications, and integration strategies. Organizations must approach OCR implementation as a strategic initiative that requires careful planning, robust architectural design, and comprehensive change management strategies. The development of appropriate governance frameworks and operational procedures ensures that organizations can fully leverage the technology's capabilities while maintaining necessary controls and compliance requirements.
The future of enterprise data entry, shaped by continuing technological evolution and changing business requirements, will likely see increasing integration of OCR capabilities into broader digital transformation initiatives. Organizations that successfully implement and leverage OCR technology position themselves advantageously for this future, equipped with the tools and capabilities necessary to handle increasing document processing demands while maintaining competitive advantage. As the technology continues to evolve, its role in organizational operations will likely expand, offering new possibilities for efficiency, automation, and innovation in document processing workflows.
In conclusion, the transformation of data entry through OCR technology represents not just a technological advancement but a fundamental reimagining of how organizations handle information processing and management. The technology's ability to combine high accuracy levels with efficient processing capabilities, while continuously evolving through AI and machine learning advancements, makes it an essential tool for organizations seeking to maintain competitive advantage in an increasingly digital business environment. As we look to the future, the continued evolution of OCR technology promises to bring new capabilities and opportunities that will further transform how organizations approach document processing and data management challenges.