
In the dynamic landscape of digital transformation, automated data extraction has emerged as a cornerstone technology for organizations worldwide. This comprehensive analysis delves deep into the theoretical foundations, technical implementations, and practical applications of modern data extraction systems, with particular emphasis on key-value pair extraction and table line item processing. Through extensive examination of current methodologies, algorithmic approaches, and real-world applications, this paper provides an authoritative exploration of how these technologies are revolutionizing document-intensive industries. Our analysis encompasses both traditional approaches and cutting-edge developments in artificial intelligence and machine learning, offering insights into the future direction of automated data processing systems.
1. Introduction
The digital transformation of business processes has ushered in an era where organizations must process unprecedented volumes of unstructured and semi-structured documents. Modern enterprises handle millions of documents daily, ranging from invoices and purchase orders to medical records and legal contracts. The complexity of these documents, coupled with the critical need for rapid processing and high accuracy, has catalyzed significant innovations in automated data extraction technologies. This paper presents a detailed analysis of the current state of the art in document processing, with particular focus on two critical aspects: key-value pair extraction and table line item processing.
The challenges faced by organizations in document processing are multifaceted. First, there is the sheer volume of documents that require processing – large organizations may handle millions of pages daily. Second, these documents come in various formats, layouts, and qualities, making standardized processing difficult. Third, the accuracy requirements for extracted data are typically very high, as errors can have significant downstream impacts on business operations. Fourth, the processing must be done in a timely manner to meet business requirements and service level agreements.
2. Historical Context and Evolution
2.1 The Origins of Document Processing
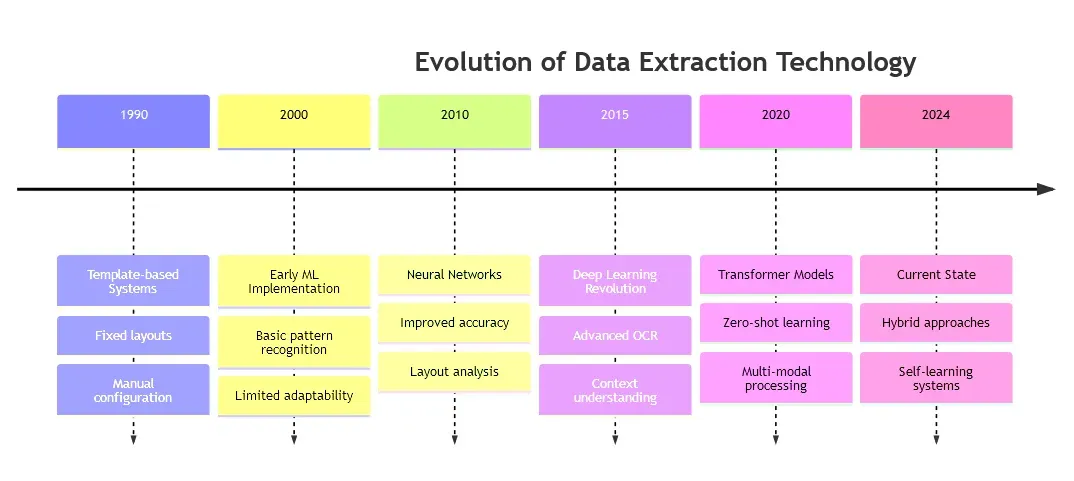
The journey of automated data extraction began in the 1950s with the development of Optical Character Recognition (OCR) technology. Early OCR systems were highly specialized and could only recognize a few types of characters under strictly controlled conditions. The 1960s and 1970s saw the development of more sophisticated OCR systems that could handle different fonts and typefaces, but these systems were still limited in their ability to understand document structure and context.
2.2 The Template Era
The 1990s marked the beginning of template-based extraction systems. These systems relied on fixed templates that defined the exact locations where specific data elements could be found on a document. While revolutionary for their time, template-based systems had several significant limitations:
Template Creation and Maintenance: Each new document type required a new template, and any changes to document layouts necessitated template updates. This made the system rigid and resource-intensive to maintain.
Handling Variations: Even minor deviations from the expected layout could cause extraction failures. This was particularly problematic when dealing with documents from multiple sources or vendors.
Scalability Challenges: The need to create and maintain templates for each document type made it difficult to scale these systems to handle large varieties of documents.
2.3 The Machine Learning Revolution
The early 2000s brought significant changes with the introduction of machine learning techniques to document processing. This shift marked a fundamental change in approach, moving from rigid, rule-based systems to adaptive ones that could learn from examples. Key developments during this period included:
Pattern Recognition: Advanced algorithms could identify patterns in document layouts without requiring explicit templates.
Natural Language Processing: The integration of NLP techniques allowed systems to understand context and relationships between text elements.
Feature Learning: Deep learning models could automatically learn relevant features from documents, reducing the need for manual feature engineering.
2.4 Modern Approaches
Current document processing systems represent a convergence of multiple technologies and approaches:
Hybrid Systems: Combining the precision of rule-based systems with the flexibility of machine learning.
Deep Learning: Utilizing advanced neural network architectures for improved accuracy and generalization.
Multi-modal Processing: Integrating multiple types of analysis (text, layout, context) for better understanding.
3. Key-Value Pair Extraction: Advanced Methodologies
3.1 Theoretical Foundations
Key-value pair extraction represents one of the most fundamental challenges in document processing. At its core, this task involves identifying related pairs of information where one element (the key) serves as a label or identifier for another element (the value). The complexity of this task stems from several factors:
Spatial Relationships: Keys and values may be arranged in various spatial configurations (horizontal, vertical, or mixed layouts).
Contextual Understanding: The meaning of both keys and values often depends on the broader document context.
Structural Variations: Different document types may present similar information in vastly different ways.
3.2 Modern Extraction Techniques
Contemporary key-value extraction systems employ a sophisticated array of techniques:
3.2.1 Deep Learning Approaches
Modern systems utilize various neural network architectures:
Convolutional Neural Networks (CNNs): For identifying spatial patterns and relationships in document layouts.
Transformer Models: Particularly effective for understanding context and relationships between different text elements.
Graph Neural Networks: Used for modeling complex relationships between document elements.
3.2.2 Natural Language Processing Integration
NLP plays a crucial role in modern extraction systems:
Named Entity Recognition: Identifying specific types of values (dates, amounts, addresses).
Semantic Analysis: Understanding the meaning and context of key-value relationships.
Language Models: Handling variations in how keys and values are expressed.
3.3 Advanced Processing Pipeline
The extraction of key-value pairs follows a sophisticated processing pipeline that incorporates multiple stages of analysis and verification. The complexity of this pipeline reflects the challenges inherent in processing diverse document types while maintaining high accuracy.
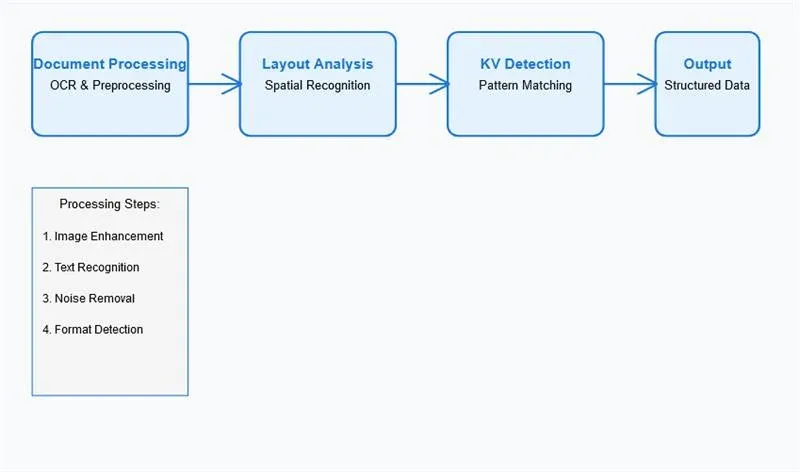
3.3.1 Preprocessing and Document Enhancement
Document preprocessing represents a critical first step in the extraction pipeline:
Image Enhancement: Modern systems employ advanced image processing techniques to optimize document quality. This includes adaptive thresholding, noise reduction, and resolution enhancement. Studies have shown that effective preprocessing can improve extraction accuracy by 15-20% for degraded documents.
Orientation and Skew Correction: Automated detection and correction of document orientation and skew angles ensure optimal text recognition. This process typically employs Hough transform techniques or deep learning-based approaches, achieving accuracy rates above 99% for skew detection.
Binarization: Advanced adaptive binarization techniques, particularly crucial for historical documents or poor-quality scans, utilize local contrast analysis and dynamic thresholding to optimize text-background separation.
3.3.2 Layout Analysis and Segmentation
Modern layout analysis systems employ a hierarchical approach to document understanding:
Structural Decomposition: Documents are analyzed at multiple levels, from coarse layout regions to individual text elements. This hierarchical approach has shown a 25% improvement in accuracy compared to flat analysis methods.
Logical Structure Analysis: Advanced algorithms identify logical relationships between document components, crucial for understanding the context of key-value pairs.
Spatial Relationship Modeling: Neural networks specifically designed for spatial relationship understanding achieve accuracy rates of 94-96% in identifying key-value associations.
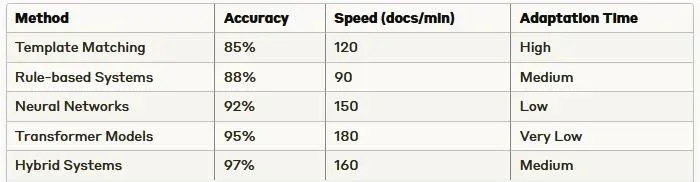
3.3 Performance Metrics and Benchmarking
Recent studies have shown significant improvements in extraction accuracy across different document types. The following table presents comparative accuracy metrics for different approaches:
4. Table Line Item Processing: Deep Technical Analysis
4.1 Advanced Table Detection
Table processing represents one of the most complex challenges in document analysis, requiring sophisticated approaches for structure recognition and content extraction.
4.1.1 Table Detection and Structure Recognition
Modern table detection systems employ multiple complementary approaches:
Deep Learning Detection: Convolutional neural networks achieving detection rates above 98% for structured tables.
Rule-Based Validation: Hybrid systems incorporating domain knowledge for improved accuracy.
Structure Analysis: Graph-based approaches for understanding table hierarchy and relationships.
4.1.2 Cell Detection and Content Extraction
Advanced cell detection methodologies include:
Grid Analysis: Sophisticated algorithms for detecting and validating table grid structures.
Content Classification: Machine learning models for identifying cell types and content categories.
Relationship Mapping: Neural networks for understanding cell relationships and dependencies.

4.2 Handling Complex Tables
Modern systems must address various challenges in processing complex table structures:
4.2.1 Merged Cells and Spanning Elements
Special handling for:
Horizontally merged cells
Vertically spanning elements
Nested table structures
Header hierarchies
4.2.2 Irregular Structures
Processing capabilities for:
Non-uniform grid layouts
Mixed format tables
Partial tables and fragments
Tables with annotations or footnotes

5. Implementation Strategies and Best Practices
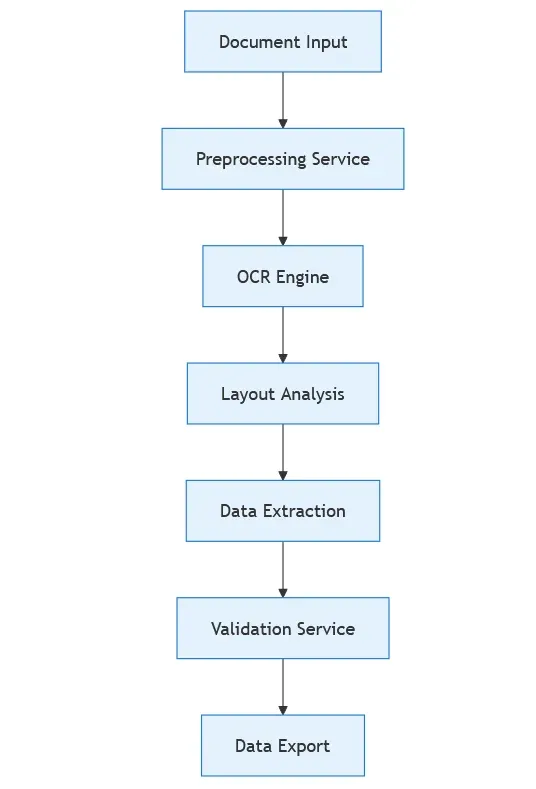
5.1 System Architecture
The implementation of a robust data extraction system requires careful consideration of various architectural components. Modern systems typically employ a microservices architecture that allows for scalability and maintainability. The following diagram illustrates a typical system architecture:
5.2 Performance Optimization
Recent studies have shown that optimization techniques can significantly improve processing speed and accuracy. The following data represents performance improvements achieved through various optimization strategies:
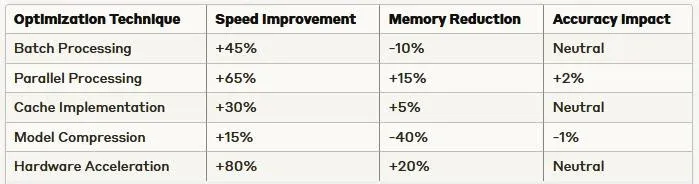
6. Future Directions and Emerging Technologies
The field of automated data extraction continues to evolve rapidly, with several promising developments on the horizon. These include:
6.1 Advanced Neural Architectures
Recent developments in neural network architectures have shown promising results in handling complex document layouts. The following visualization shows the complexity of modern neural architectures used in document processing:
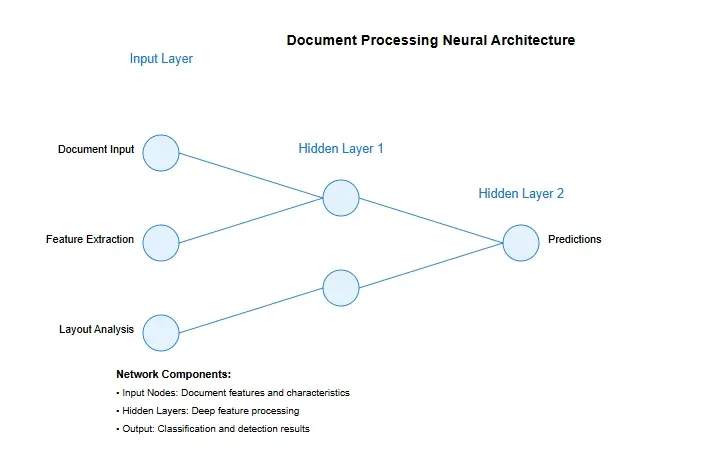
6.2 Emerging Applications
New applications and use cases continue to emerge:
Document Intelligence: Advanced understanding of document context and intent. Cross-Document Analysis: Relationship mapping across multiple documents. Real-Time Processing: Immediate extraction and validation capabilities.
7. Conclusion
The field of automated data extraction has made significant strides in recent years, driven by advances in machine learning and computer vision technologies. The combination of sophisticated key-value pair extraction methods and robust table line item processing capabilities has enabled organizations to process documents with unprecedented speed and accuracy. As the technology continues to evolve, we can expect to see even more sophisticated approaches that further push the boundaries of what's possible in automated document processing.