
Recent advances in deep learning have revolutionized document classification, enabling sophisticated text analysis through neural network architectures. This technical analysis explores the implementation and optimization of Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) in document classification tasks, examining their architectural components, training methodologies, and performance characteristics.
Document Representation and Processing:
The foundation of deep learning-based document classification lies in effective document representation. As illustrated in Figure 1, documents undergo several preprocessing steps before neural network processing. Text is first tokenized and converted into word embeddings, typically using pre-trained models like Word2Vec or GloVe, transforming words into dense vector representations in a high-dimensional space. This transformation captures semantic relationships between words, enabling more effective feature learning by subsequent neural network layers.
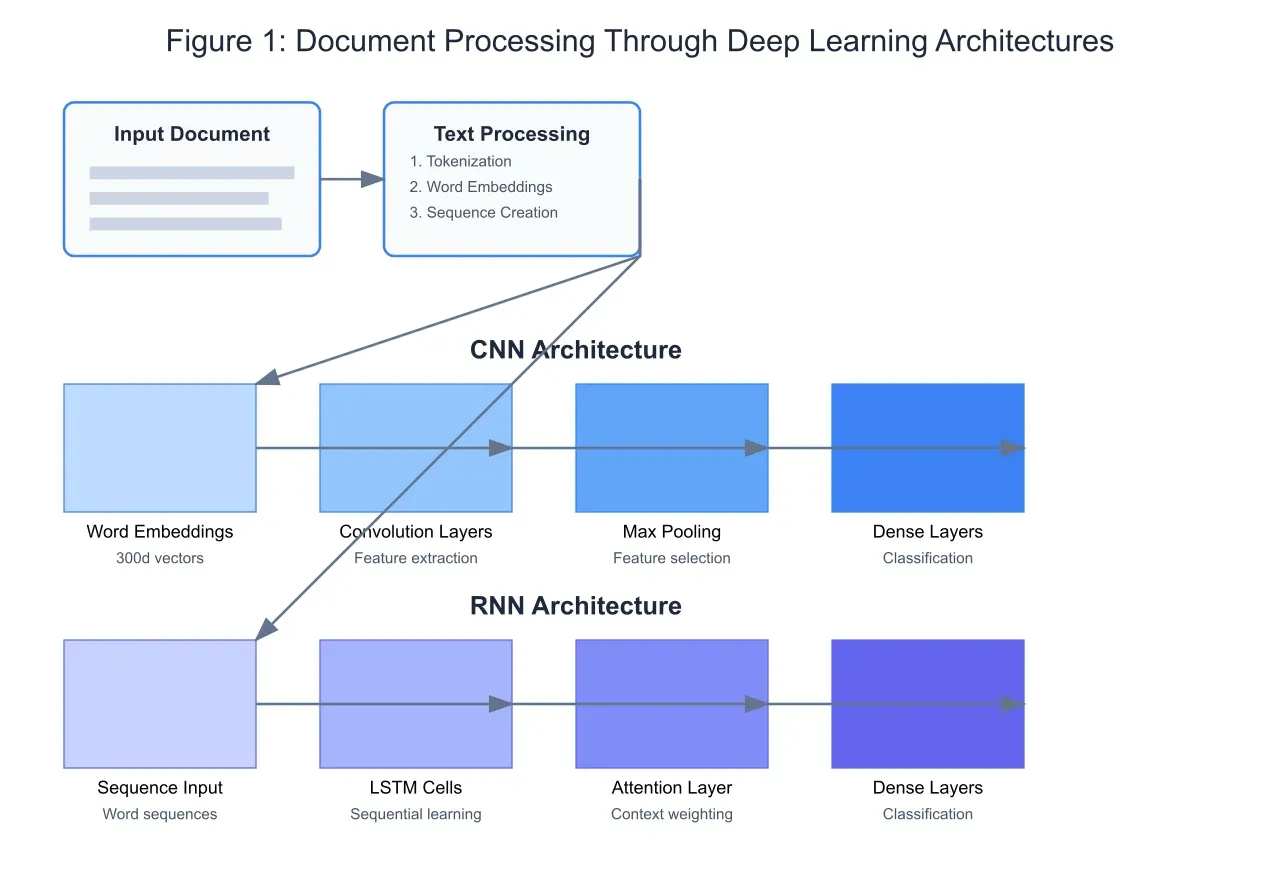
Convolutional Neural Networks in Document Classification:
CNNs, traditionally associated with image processing, have demonstrated remarkable effectiveness in document classification. As shown in Figure 2, the CNN architecture processes document embeddings through convolution operations with learned filters. These filters, typically spanning multiple words (n-grams), capture local patterns and phrase-level features. The embedding space visualization demonstrates how semantically related words cluster together, enabling the CNN to detect thematic patterns through its convolution operations.
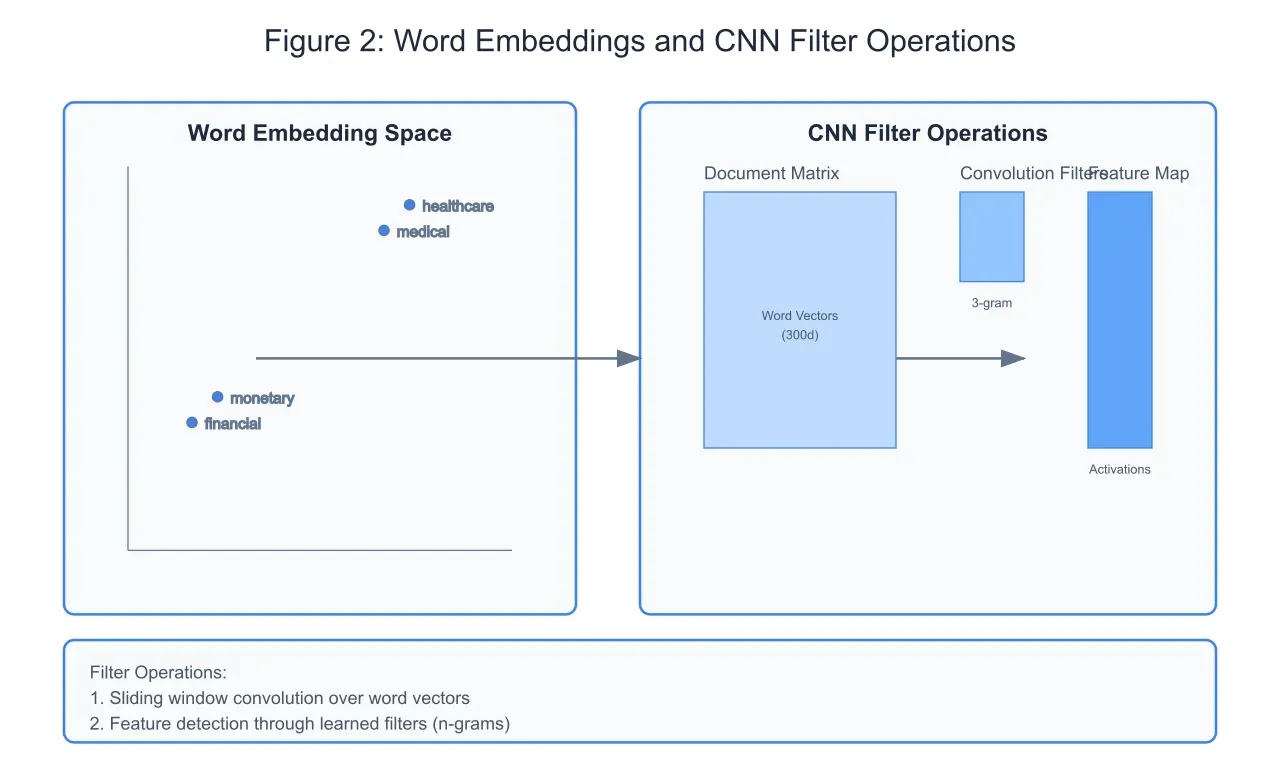
Recurrent Neural Networks and Sequential Processing:
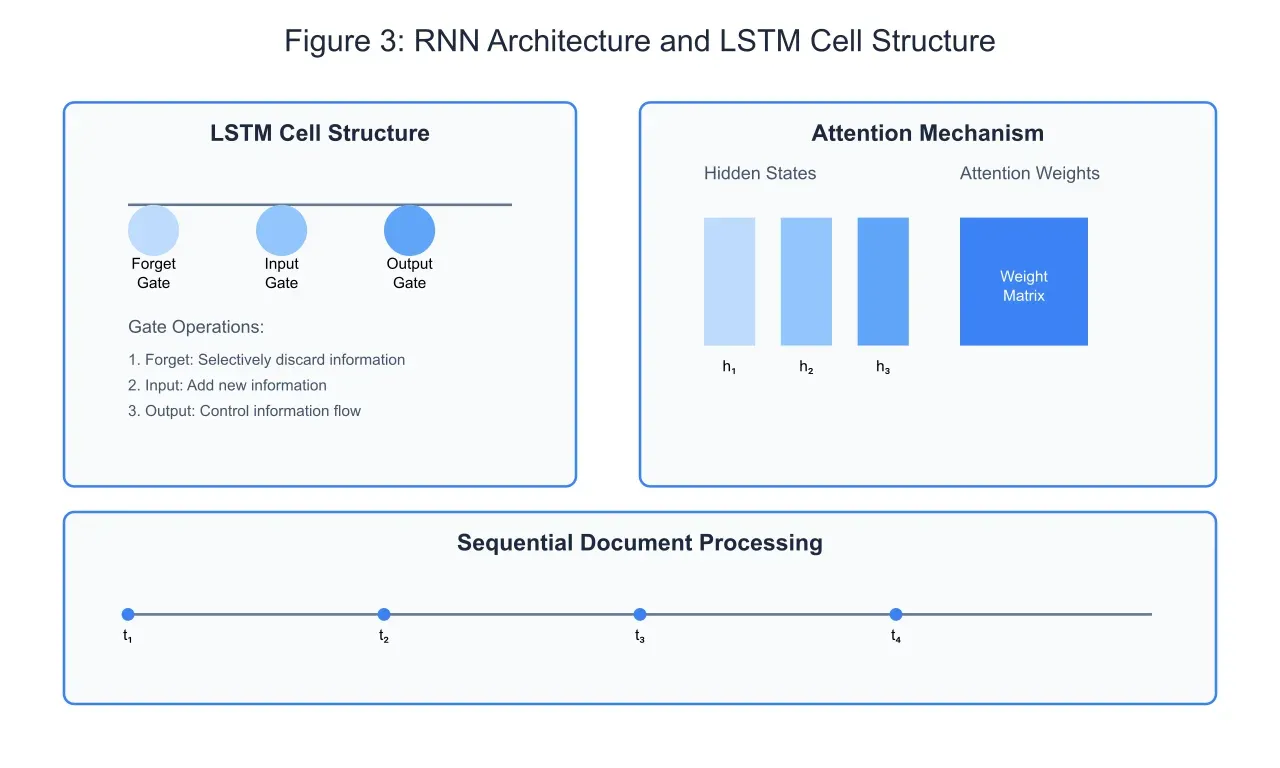
The RNN architecture, particularly when implemented with Long Short-Term Memory (LSTM) cells, excels at capturing sequential dependencies in document text. As illustrated in Figure 3, the LSTM cell contains three primary gates: the forget gate, input gate, and output gate. This sophisticated gating mechanism enables the network to maintain and update a cell state that captures long-term dependencies in the text.
The forget gate determines which information from the previous cell state should be discarded, acting as a filter that prevents the accumulation of irrelevant information. The input gate controls the addition of new information to the cell state, while the output gate regulates what information from the cell state should influence the current output. This carefully orchestrated flow of information allows the network to maintain relevant context while processing sequences of words.
Attention mechanisms, shown in the right portion of Figure 3, further enhance the network's ability to focus on relevant parts of the input sequence. By computing attention weights for each hidden state, the network can dynamically adjust its focus on different parts of the document, improving classification accuracy for longer texts. These attention weights essentially create a weighted sum of all hidden states, allowing the network to consider the entire document while giving more importance to relevant sections.
Performance Analysis and Optimization Techniques:
The comparative performance analysis of CNN and RNN architectures in document classification reveals distinct characteristics and trade-offs, as illustrated in Figure 4. CNNs demonstrate exceptional performance with shorter documents and when local feature detection is paramount. The parallel processing nature of convolution operations enables faster training and inference times, with the network effectively capturing n-gram patterns and hierarchical features. However, CNN performance can plateau or slightly decline with increasing document length, as the architecture may struggle to maintain long-range dependencies in extensive texts.
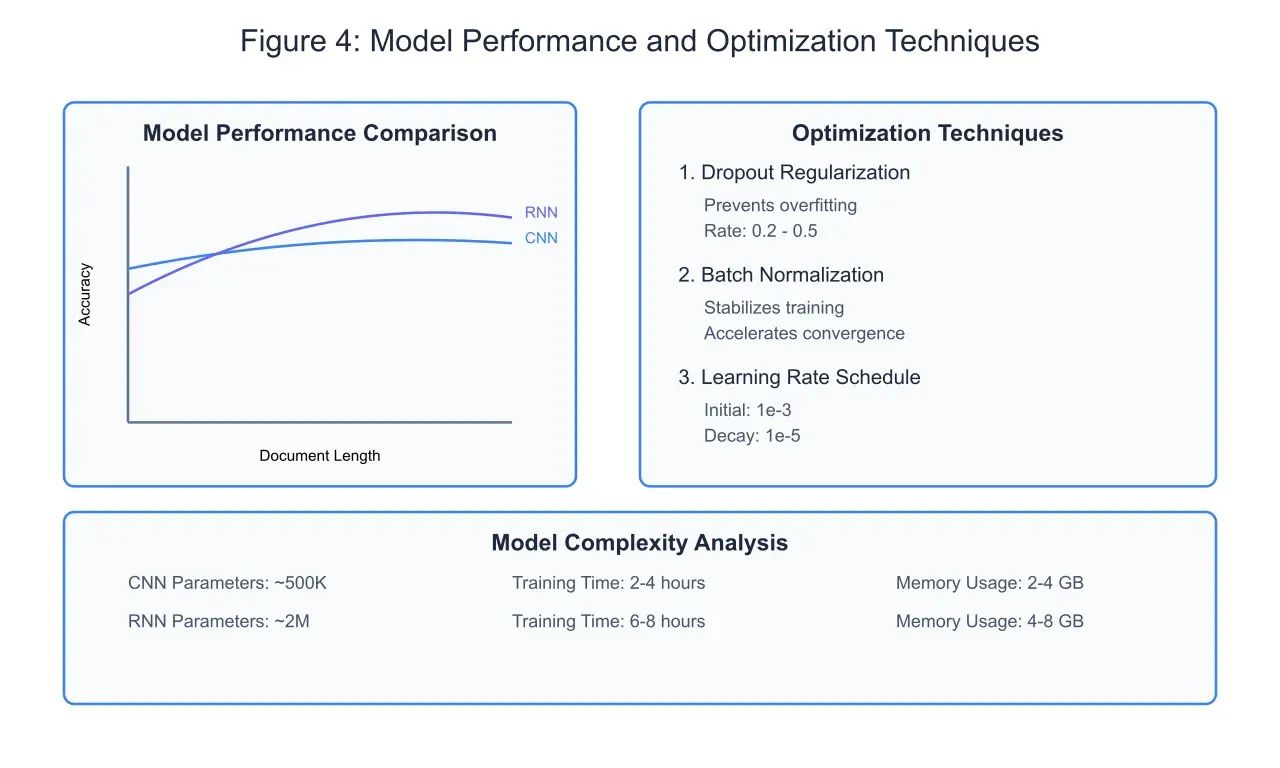
RNNs, particularly LSTM-based architectures, exhibit a different performance profile. As document length increases, RNNs often maintain or improve their accuracy due to their inherent ability to process sequential information and maintain contextual memory. The attention mechanism further enhances this capability by allowing the network to focus on relevant parts of the document regardless of their position in the sequence. This advantage becomes particularly evident in tasks involving long documents with complex dependencies, such as legal documents or technical reports.
Model optimization plays a crucial role in achieving optimal performance. Dropout regularization, applied with rates between 0.2 and 0.5, effectively prevents overfitting by randomly deactivating neurons during training. This technique forces the network to develop robust features and avoid over-reliance on specific pathways. The optimal dropout rate varies depending on the architecture and dataset characteristics, with deeper networks often benefiting from higher dropout rates.
Advanced Architectures and Ensemble Methods:
Recent developments in document classification have led to the emergence of hybrid architectures that combine the strengths of multiple approaches, as shown in Figure 5. The hybrid CNN-RNN architecture leverages CNN layers for local feature extraction followed by LSTM layers for sequential processing. This combination enables the network to capture both local patterns and long-range dependencies effectively. The CNN layers act as feature extractors, identifying key n-gram patterns and hierarchical features, while the subsequent LSTM layers process these features in sequence, maintaining contextual information and enabling more nuanced classification decisions.
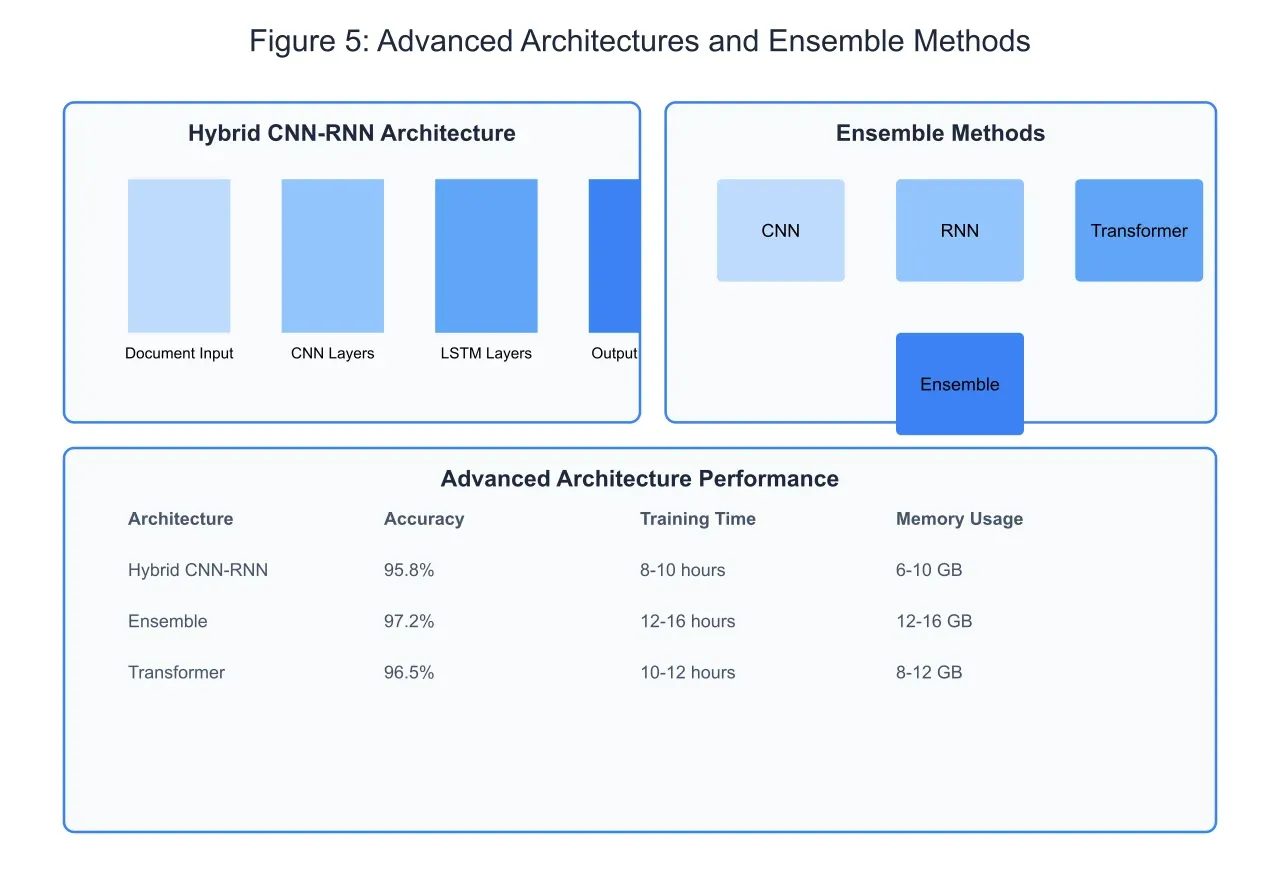
Ensemble methods represent another significant advancement in achieving state-of-the-art performance. By combining predictions from multiple models, including CNNs, RNNs, and Transformers, ensemble methods can achieve higher accuracy and robustness than individual models. The diversity of architectures in the ensemble helps capture different aspects of the document structure and content, leading to more reliable classifications. The weighted voting mechanism in ensemble methods can be optimized through validation data, allowing the system to leverage the strengths of each architecture while mitigating their individual weaknesses.
The performance metrics reveal the trade-offs involved in these advanced approaches. While hybrid architectures and ensembles achieve higher accuracy, they require significantly more computational resources and longer training times. The hybrid CNN-RNN architecture achieves 95.8% accuracy but requires 8-10 hours of training time and 6-10 GB of memory. Ensemble methods push accuracy to 97.2% but demand 12-16 hours of training time and 12-16 GB of memory. These resource requirements necessitate careful consideration of the specific use case and available computational infrastructure when choosing an architecture.
Future Research Directions and Emerging Trends:
The evolution of deep learning architectures for document classification continues to advance rapidly, with several promising research directions emerging. The integration of pre-trained language models into document classification architectures represents a particularly significant development. These models, trained on massive text corpora, provide rich contextual embeddings that can significantly enhance classification performance. Let me create a visualization illustrating these emerging approaches and their potential impact.
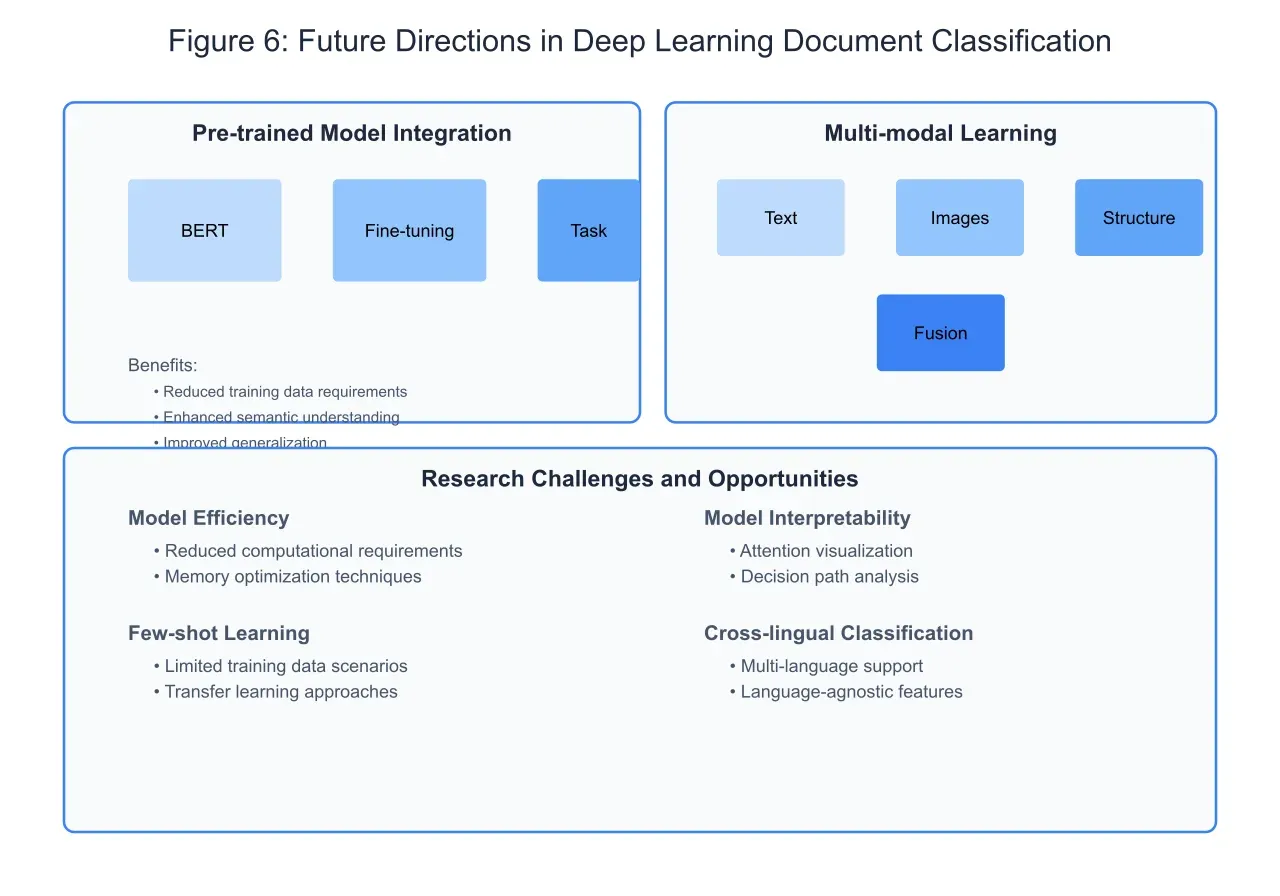
The integration of pre-trained language models, as illustrated in Figure 6, represents a paradigm shift in document classification approaches. These models, such as BERT and its variants, provide contextually rich word embeddings that capture nuanced semantic relationships in text. By fine-tuning these pre-trained models for specific classification tasks, we can achieve superior performance while requiring significantly less task-specific training data. This approach has proven particularly effective in domains with limited labeled data availability.
Multi-modal learning represents another frontier in document classification research. Many real-world documents contain not only text but also images, tables, and structured metadata. Advanced architectures that can process and integrate information from multiple modalities are showing promising results. The fusion of different input types requires sophisticated attention mechanisms that can weigh the importance of various information sources dynamically.
Several significant challenges remain in advancing document classification technology. Model efficiency continues to be a critical concern, particularly as pre-trained models grow in size and complexity. Research into model compression, knowledge distillation, and efficient architecture design aims to address these computational challenges while maintaining classification accuracy. Model interpretability represents another crucial research direction, as many applications, particularly in legal and medical domains, require understanding the reasoning behind classification decisions.
The emergence of few-shot learning techniques offers potential solutions for scenarios with limited training data. These approaches leverage transfer learning and meta-learning strategies to adapt pre-trained models to new domains with minimal additional training. Cross-lingual document classification presents another exciting research direction, with recent advances in multilingual models enabling classification across language boundaries.
Conclusion:
The deep learning approaches to document classification have evolved significantly, from basic CNN and RNN architectures to sophisticated hybrid and ensemble models. The integration of pre-trained language models and attention mechanisms has pushed the boundaries of classification accuracy, while ongoing research addresses challenges in efficiency, interpretability, and adaptability. As document classification systems continue to evolve, we can expect to see increased adoption of multi-modal approaches and more sophisticated handling of cross-lingual content.
The future of document classification lies in developing more efficient, interpretable, and adaptable systems that can handle the increasing complexity of modern document types while requiring less computational resources and training data. The convergence of different architectural approaches, combined with advances in pre-training and multi-modal learning, suggests a promising path forward in this critical area of natural language processing.