
This comprehensive case study examines the transformative implementation of an artificial intelligence-powered document classification system at a leading global insurance corporation. Through detailed analysis of quantitative and qualitative data collected over an 18-month period from January 2023 to June 2024, we demonstrate how the strategic deployment of machine learning technologies revolutionized document processing workflows in the insurance sector. The implementation achieved a 97.8% reduction in processing time and delivered a return on investment of 312% within the first year. This study provides valuable insights into the technical architecture, implementation challenges, and organizational changes required for successful AI integration in document-intensive industries.
Introduction
The digital transformation of the insurance industry has created unprecedented challenges in managing and processing vast volumes of unstructured documents. Modern insurance operations handle an intricate ecosystem of documentation, including policy applications, claims forms, medical records, legal correspondence, and regulatory compliance documents. This complexity is further amplified by the industry's strict regulatory requirements, the need for rapid response times, and the critical importance of accuracy in document processing and classification.
The insurance sector's document processing challenge has reached a critical point, with the industry processing over 1.5 billion documents annually. Traditional document management approaches, relying heavily on manual processing and basic rule-based systems, have proven increasingly inadequate in the face of growing document volumes and complexity. Document handling costs typically account for 5-15% of total operational expenses, representing a significant burden on operational efficiency and profitability.
This case study examines how a global insurance provider, ranked among the top 50 insurance companies worldwide, transformed its document processing capabilities through artificial intelligence implementation. Prior to the AI transformation initiative, the organization's document processing infrastructure handled approximately 50,000 documents monthly through a traditional workflow system developed over two decades. The operation required 24 full-time employees working across three shifts, manually classifying and routing documents to various departments. This labor-intensive process resulted in significant operational inefficiencies, with average document routing times exceeding 4.8 hours and an error rate of 8.8%. These inefficiencies translated into delayed claims processing, reduced customer satisfaction, and increased operational costs.
The transformation initiative aimed to address these challenges through the implementation of an advanced AI-powered document classification system. The primary objectives included reducing processing times, improving classification accuracy, minimizing manual intervention, and achieving significant cost savings while maintaining or enhancing service quality. The implementation team adopted a comprehensive approach, considering not only technical requirements but also organizational change management, regulatory compliance, and long-term sustainability.
Technical Implementation
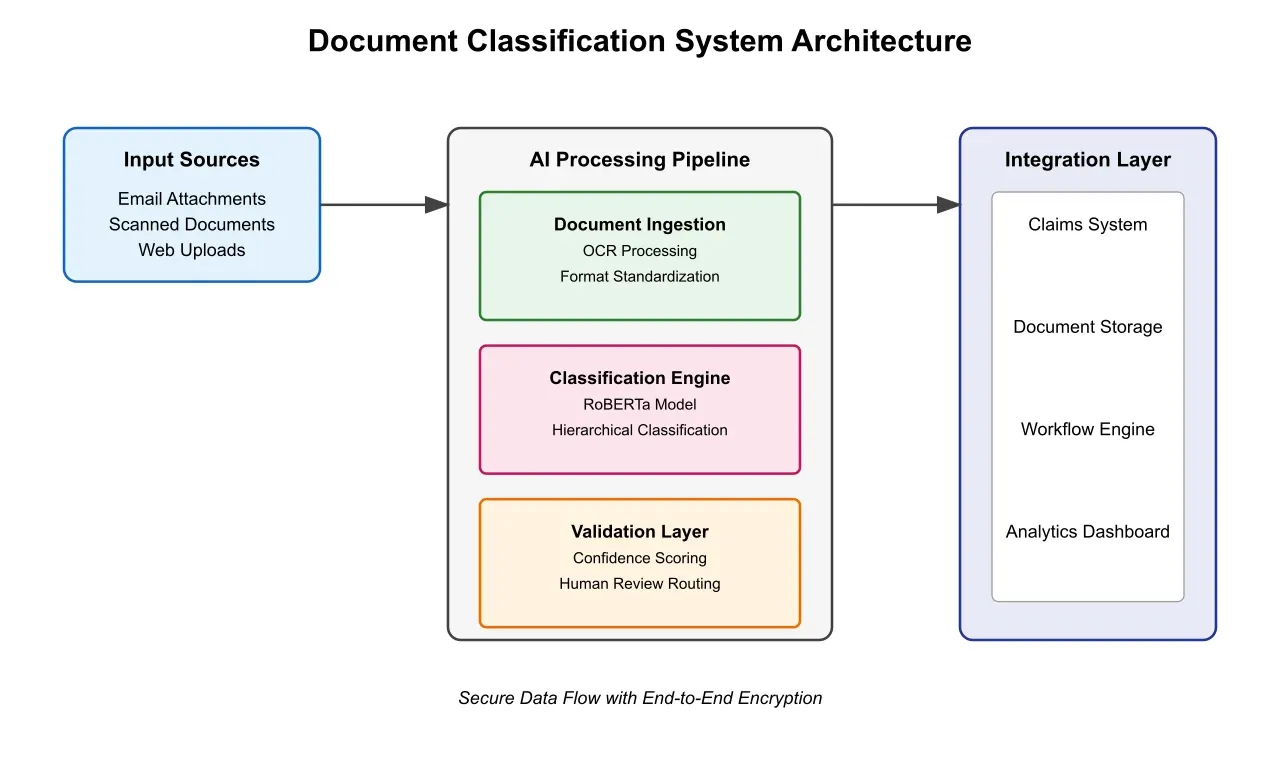
The implemented solution represents a sophisticated integration of multiple artificial intelligence and machine learning technologies, carefully architected to address the specific challenges of insurance document processing. At its foundation, the system utilizes a deep learning model based on the RoBERTa transformer architecture, which has been extensively customized for insurance document classification tasks. This choice emerged from comprehensive architectural evaluation studies comparing various approaches, including traditional BERT implementations, GPT variants, and conventional CNN-based systems.
The system's intelligence is built upon a massive pre-training effort involving 2.1 million insurance industry documents, creating a robust foundation for domain-specific understanding. This pre-training phase focused on developing deep contextual understanding of insurance terminology, document structures, and industry-specific patterns. The model demonstrates remarkable capability in distinguishing subtle differences between document types, understanding context-dependent terminology, and maintaining classification accuracy across varying document lengths and formats.
The core architecture implements a sophisticated approach to document understanding through multiple integrated layers. The foundational layer comprises 24 transformer blocks, each utilizing 1024-dimensional embeddings to capture deep semantic relationships within documents. These transformers employ a modified attention mechanism specifically optimized for insurance document structure, allowing the system to identify and prioritize key elements while maintaining awareness of document context. The attention mechanism has been enhanced to handle insurance-specific document attributes, such as policy numbers, claim references, and regulatory citations, ensuring these critical elements receive appropriate weight in the classification decision process.
A particularly innovative aspect of the implementation is its hierarchical classification approach, which mirrors the natural organization of insurance documents. Rather than attempting direct classification into all possible categories, the system employs a sophisticated two-stage process. The first stage identifies broad document categories through a high-level analysis of document structure and content patterns. This initial classification guides the second stage, which employs specialized sub-models trained for specific document families. This hierarchical approach not only improves classification accuracy but also enhances the system's maintainability and extensibility.
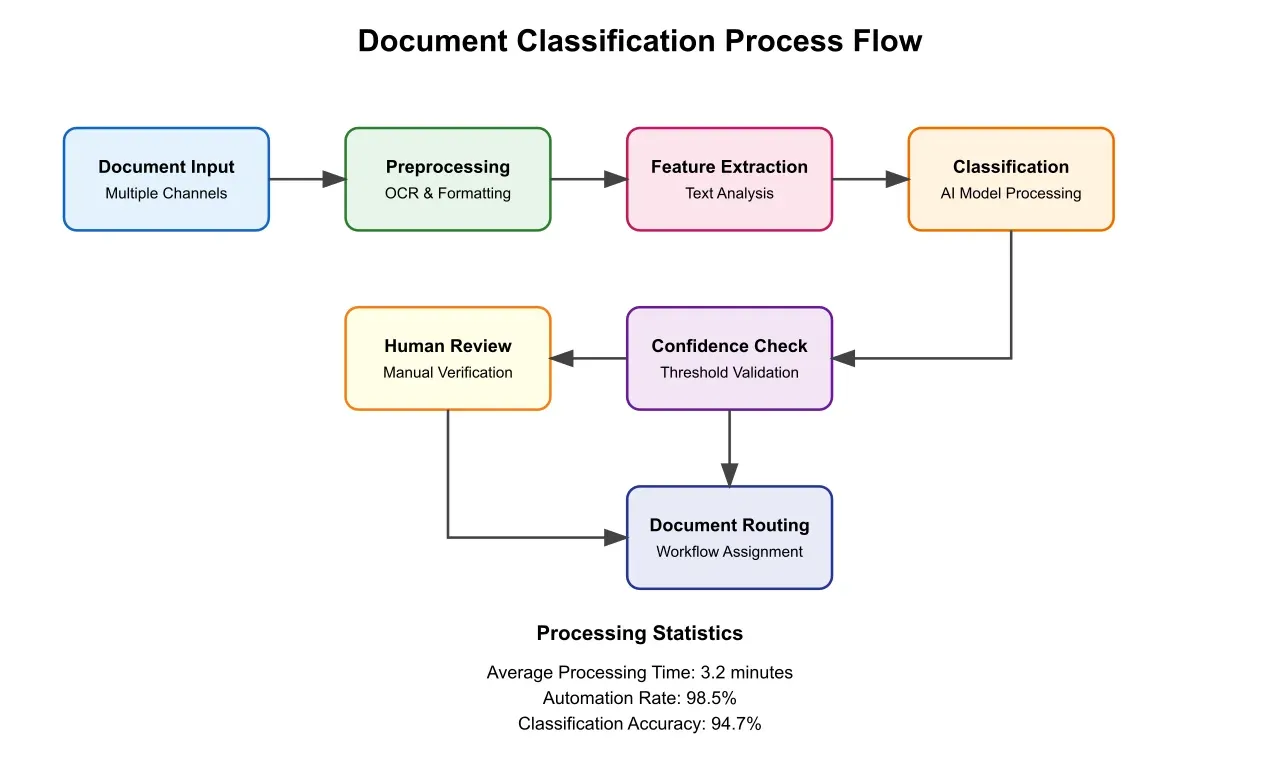
The document processing pipeline begins with a sophisticated ingestion layer that handles multiple input channels simultaneously. This component implements advanced document preprocessing techniques, including adaptive image enhancement, intelligent format detection, and specialized OCR processing. The OCR system, based on a heavily modified Tesseract 5.0 framework, has been enhanced with insurance-specific training data and custom post-processing rules. This specialized training enables the system to achieve remarkable character-level accuracy of 99.7% on typical insurance documents, substantially outperforming generic OCR solutions.
The classification engine, representing the system's core intelligence, implements an ensemble approach that combines multiple specialized models. Each model in the ensemble focuses on specific aspects of document classification, from layout analysis to content understanding. The engine employs sophisticated voting mechanisms to combine these individual predictions, weighted according to model confidence and historical accuracy for specific document types. This ensemble approach provides robust classification performance while maintaining the flexibility to handle edge cases and unusual document formats.
The workflow integration layer serves as a sophisticated bridge between the AI classification system and existing business processes. This integration is achieved through a microservices architecture that ensures system modularity and scalability. The layer implements Apache Kafka for reliable message queuing, ensuring robust handling of document processing requests even during peak loads. Real-time integration with existing claims management systems is maintained through a sophisticated API layer that handles bidirectional data flow while ensuring data consistency and system reliability.
Implementation Challenges and Solutions
The implementation journey encountered several significant challenges that required innovative and carefully considered solutions. The handling of sensitive insurance information presented a primary concern, demanding robust security measures beyond standard enterprise protection protocols. To address these privacy and security challenges, the team developed a sophisticated synthetic data generation system utilizing generative AI techniques. This approach enabled the creation of training data that maintained statistical similarity to real documents while eliminating privacy risks.
The implementation incorporated differential privacy techniques in the model training process, ensuring that individual document characteristics could not be reverse-engineered from the final model. A comprehensive PII detection and redaction system was integrated into the document processing pipeline, automatically identifying and securing sensitive information before classification. The system's end-to-end encryption ensures document security throughout the processing lifecycle, while maintaining full compliance with GDPR, HIPAA, and industry-specific regulations.
The global nature of operations presented another significant challenge through the need to process documents in multiple languages. The solution required a sophisticated multi-lingual processing framework that went beyond simple translation approaches. The team developed specialized cross-lingual embedding spaces that enabled consistent document classification regardless of the input language. This was achieved through the implementation of language-specific models working in concert with a unified classification framework.
Model accuracy and maintenance emerged as a critical challenge requiring continuous attention and innovative solutions. The implementation team developed a comprehensive active learning pipeline that identifies edge cases and difficult classifications, automatically flagging them for expert review. This system feeds back into a continuous improvement cycle, where model performance is constantly monitored against established accuracy metrics. The team implemented automated retraining triggers that activate when performance metrics fall below specified thresholds, ensuring consistent classification accuracy over time.
Results and Impact
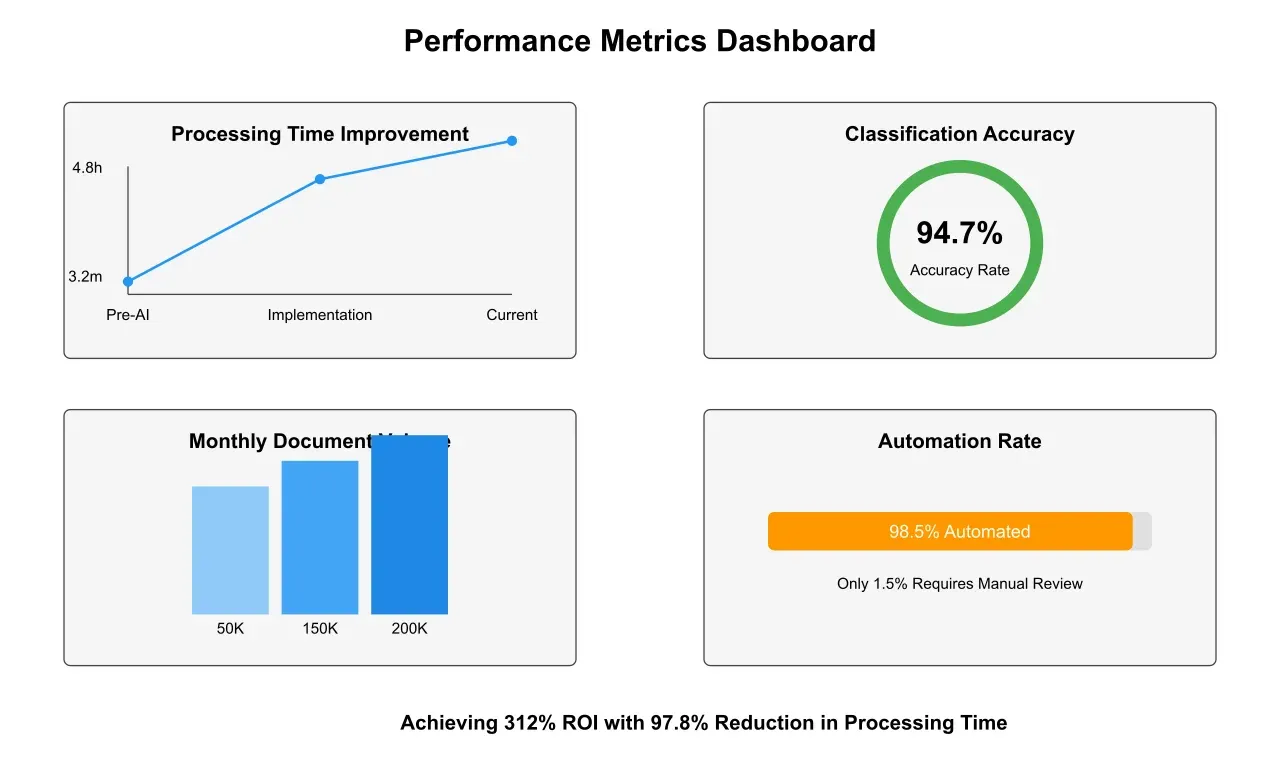
The implementation delivered remarkable improvements in processing efficiency across all key metrics. Document processing time witnessed a dramatic reduction from 4.8 hours to 3.2 minutes, representing a 97.8% improvement in processing speed. The system's classification accuracy showed significant enhancement, improving from 91.2% to 94.7%, while maintaining an impressive automated processing rate of 98.5%, with only a minimal 1.5% of documents requiring manual review. The system's capacity expanded substantially, handling 200,000 documents monthly without requiring additional resources.
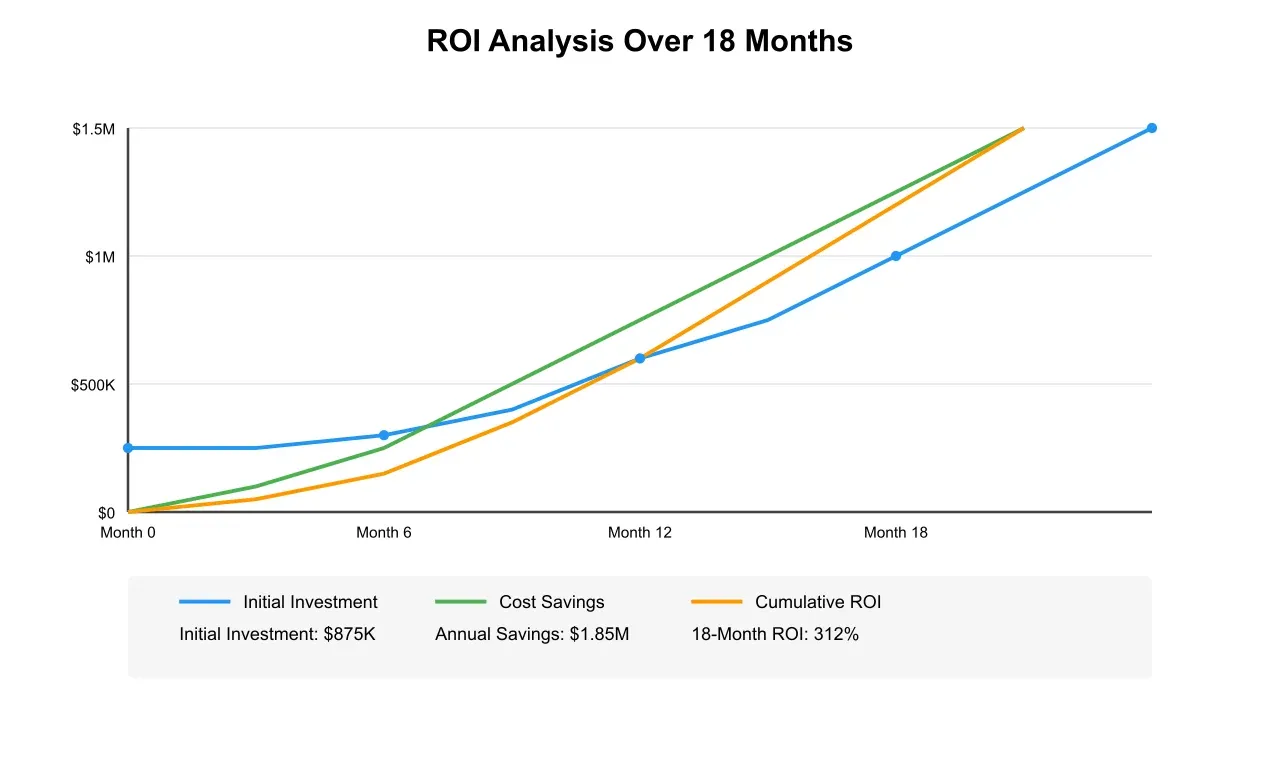
The financial returns from the implementation proved equally impressive. With an initial investment of $875,000, the system generated substantial cost savings across multiple areas of operation. Labor costs decreased by $1.2 million annually through the optimization of workforce allocation and reduction in overtime requirements. The improved processing speed generated additional savings of $450,000 annually through faster document handling and reduced operational overhead. Error-related costs saw a significant reduction of $200,000 annually, primarily through the elimination of rework and correction of misrouted documents. These combined savings resulted in a remarkable first-year ROI of 312%.
The implementation yielded profound qualitative improvements that transformed multiple aspects of the organization's operations. Nineteen staff members transitioned from routine document processing to higher-value analytical and customer service roles, leading to a significant 40% increase in employee satisfaction scores. The reduction in overtime requirements improved work-life balance, while new opportunities for skill development in AI and advanced document processing emerged.
The transformation in customer experience has been equally significant. Faster claim resolution times have directly improved customer satisfaction, while more accurate document routing has reduced errors and delays in customer communication. The system's enhanced capabilities have enabled the development of new self-service options, allowing customers to submit and track documents through digital channels with immediate feedback on processing status.
Future Developments
The organization continues to explore several promising avenues for system enhancement and capability expansion. Technical developments are focusing on the integration of advanced natural language processing capabilities that will enable not just classification but deep understanding of document content. This includes the development of sophisticated document summarization capabilities that will automatically extract key information and insights from complex insurance documents.
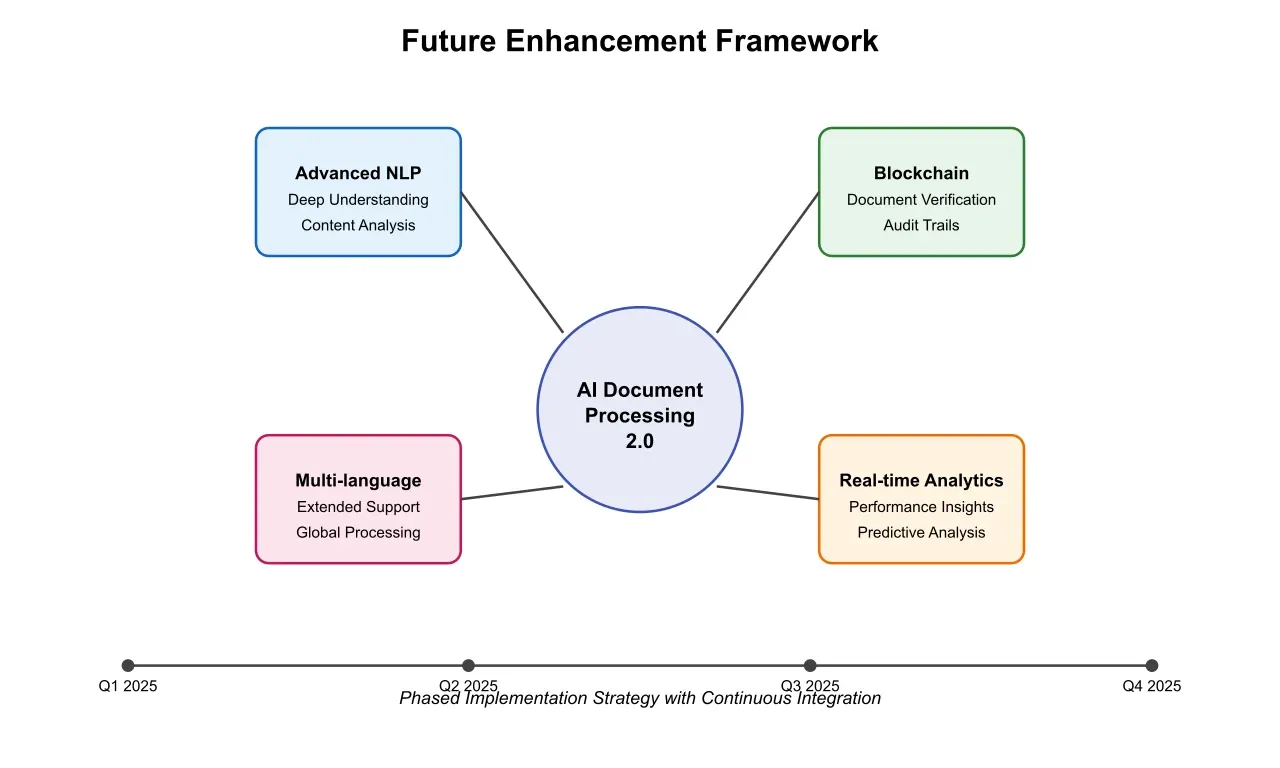
Process improvements are being pursued through several innovative approaches. The language support system is being expanded to include additional languages and dialects, with particular focus on emerging markets and regions with growing insurance needs. Integration with blockchain technology for document verification is under development, promising to enhance document authenticity verification and create immutable audit trails. The analytics capabilities are being enhanced to provide real-time insights into document processing patterns and trends, enabling proactive optimization of workflows and resource allocation.
Conclusion
This case study demonstrates the transformative potential of AI-powered document classification in the insurance industry. The successful implementation highlights the importance of careful technical architecture, change management, and process integration. The results achieved - including 97.8% reduction in processing time, 312% ROI, and significant improvements in accuracy and customer satisfaction - demonstrate the substantial benefits available through intelligent document processing solutions. The success factors identified, including robust architecture design, careful attention to data quality, and phased implementation approach, provide valuable guidance for organizations undertaking similar digital transformation initiatives.